"""
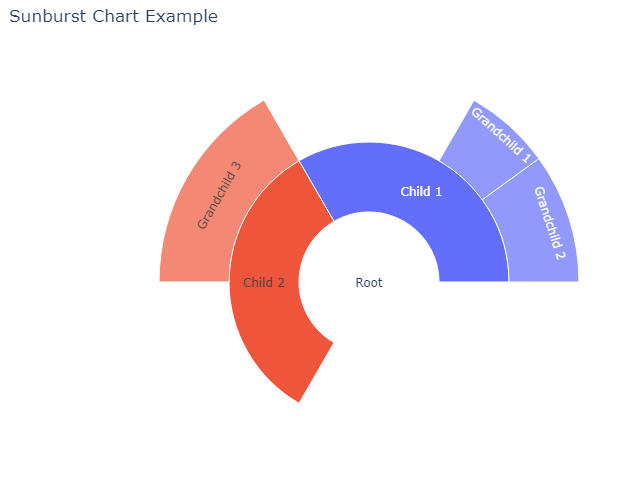
Sunburst Chart는 계층적 데이터를 시각화하는 데 사용되는 원형 차트입니다.
데이터의 루트는 중앙에 있고,
계층적으로 데이터를 표현하며, 내부에서 외부로 확장됩니다.
각 섹션은 데이터를 크기별로 구분하여 보여줍니다.
"""
import plotly.express as px
from PIL import Image
# 계층적 데이터 정의
data = dict(
labels=["Root", "Child 1", "Child 2", "Grandchild 1", "Grandchild 2", "Grandchild 3"],
parents=["", "Root", "Root", "Child 1", "Child 1", "Child 2"],
values=[10, 5, 5, 2, 3, 5]
)
# Sunburst Chart 생성
fig = px.sunburst(
data,
names='labels',
parents='parents',
values='values',
title="Sunburst Chart Example"
)
# fig.show()
# Sunburst Chart를 이미지로 저장
image_path = "sunburst_chart_001.png"
fig.write_image(image_path, width=800, height=600)
print(f"Sunburst chart saved as '{image_path}'")
# 저장된 이미지 출력
image = Image.open(image_path)
image.show() # 기본 이미지 뷰어로 열기
디지털 플랫폼의 채용 공고 광고는 비용이 거의 들지 않는다. 동시에 공고를 게시한 회사는 다양한 정보를 얻거나 여타 효과를 거둘 수 있다. 이를 테면 채용 공고만으로도 기업은 잠재적 인재 기반을 구축하거나, 시장 동향을 조사하거나, 성장 중인 기업으로서 관심을 끌 수 있다.
이러한 이유로 ‘유령 일자리’ 현상이 빠르게 증가하고 있다. 유령 일자리는 채용할 의사가 없는 회사에서 게시한 구인 공고를 말한다. 이러한 꼼수는 부정적인 사회적, 경제적 결과를 초래한다. 노동 시장의 효율성에 영향을 미치고, 지원자의 비용을 증가시키며, 연구자와 정책 입안자의 데이터 분석을 복잡하게 만든다.
헌터 응은 인기 채용 플랫폼 글래스도어의 ‘면접’ 섹션에서 약 27만 건의 리뷰를 바탕으로 연구를 진행했다. 그는 고급 자연어 처리 알고리즘으로 지원되는 LLM BERT 모델을 활용해 구직자의 면접 경험에 대한 게시물에 대해 심층 언어 분석을 수행했다. 이러한 AI 분석을 통해 그는 단순히 불합격으로 인한 속상함을 표현하는 ‘신 포도’ 게시글와 “역량에 대한 질문도 없었고, 예상 연봉에 대한 설명도 없었다”는 등의 ‘유령 면접’ 후기를 구분할 수 있었다고 전했다.
응의 LLM BERT 분석에 따르면 유령 일자리로 분류될 수 있는 채용 공고가 최대 21%에 달했다. 그에 따르면 유령 채용공고가 존재하는 여러 이유가 있다.
먼저 광고 게시 비용이 저렴한 현실이 한 이유다. 글래스도어와 같은 플랫폼 덕분에 채용공고를 게시하는 데 드는 비용이 거의 들지 않거나 전혀 들지 않는다. 따라서 기업은 실제 채용 수요와 관계없이 광고를 대량으로 게시할 수 있다.
또 잠재력 후보군을 확보할 수 있다는 점이 다른 이유다. 고도로 전문화된 직책이라면 꽤 유용할 수 있다. 즉 광고를 게시함으로써 기업은 지원서와 잠재적 후보자에 대한 정보를 수집하여 향후 채용 수요에 신속하게 대응할 수 있는 인력 풀을 확보할 수 있다.
이 밖에 유령 일자리 공고는 기업 내부 활동의 일환일 수 있다고 그는 덧붙였다. HR 부서가 이러한 방식으로 높은 활동성을 쉽게 만들어 회사에 대한 가치를 높일 수 있다는 설명이다.
거시적으로 보면 유령 일자리는 베버리지 곡선과 같은 경제 지표에 영향을 미쳐 실업률과 구인난 사이의 관계를 왜곡한다. 응은 구인 광고의 투명성을 높이고 이러한 관행을 제한할 수 있는 규제가 필요하다고 지적했다.
가짜 공고가 유해한 다른 이유
흥미롭게도 ‘유령 일자리’는 디지털 공간에서 나타나는 또 다른 부정적인 고용 현상과 관련이 있다. 2019년 메리 그레이와 싯다르타 수리 연구원이 대중화한 ‘유령 업무'(ghost work)라는 용어는 정식 고용 상태 없이 콘텐츠 마케팅이나 교정 등 디지털 공간에서 원격으로 수행되는 직무를 의미한다.
점점 더 많은 연구자와 기업이 ‘유령 일자리’ 문제를 다루고 있으며, 노동 시장에 미치는 영향과 고용주가 사용하는 전략을 분석하고 있다. 예를 들어, 마이퍼펙트레주메(MyPerfectResume)가 실시한 연구에 따르면 채용 담당자의 81%가 가짜 채용 공고를 올린 사실을 인정하는 것으로 나타났다. 이 연구의 저자는 이러한 관행의 의도를 응과 비슷하게 해석한다. 인재 풀 구축, 시장 테스트, 회사 이미지 개선 등이다.
AI 엔지니어, 데이터 과학자 또는 소프트웨어 개발자와 같은 IT 분야의 전문 직책에는 고유한 역량이 필요하다. 기업들은 이러한 전문가의 구인 가능 여부와 기대 연봉을 지속적으로 모니터링하기 위해 유령 직무를 게시한다. 기술 분야에서는 주로 인재 풀을 구축하고 전문가의 가용성을 테스트해야 할 필요성 때문에 이러한 관행이 이어지고 있다. 기업들은 또한 광고의 효과를 테스트하고 경쟁사를 모니터링하기 위해 이러한 관행을 사용한다.
허위 정보 게시로 인한 피해
올해 레주메빌더(ResumeBuilder)가 1,600명 이상의 채용 관리자를 대상으로 실시한 설문조사에서 유령 일자리 현상에 대해 더 자세히 알아볼 수 있다. 해당 설문조사에 따르면 채용 담당자의 80% 이상이 채용할 의사가 없이 채용 공고를 게시했다고 답했으며, 41%는 채용 공고의 절반 이상이 가짜라고 답했다. 기술 기업 중 40%는 지난 1년 이내에 가짜 채용공고를 게시한 바 있으며, 이 중 79%는 여전히 진행 중인 공고를 보유하고 있었다.
가짜 공고는 초급(63%), 중간급(68%), 고위급(53%), 임원(45%) 등 모든 직급에 걸쳐 있었다. 이러한 허위 정보가 가장 많이 게재되는 곳은 회사 웹사이트(72%), LinkedIn(70%), ZipRecruiter(58%), Indeed(49%), Glassdoor(48%) 등이다. 대부분의 유령 채용공고는 한 달(31%), 몇 주(28%), 경우에 따라 1년 이상(9%) 동안 활성 상태로 유지된다.
채용 담당자들은 이러한 조치를 취하는 이유도 밝혔다. 다음과 같이 다양한 이유가 제시됐다:
• 67%의 기업이 외부 인재에게 개방적이기를 원한다. • 66%는 성장하고 있다는 인상을 주고 싶다고 답했다. • 63%는 현재 직원들에게 업무량이 줄어들 것이라고 설득하려고 한다. • 62%는 현재 직원들에게 대체 불가능한 인재라는 인상을 주고 싶어 한다. • 59%는 후보자 데이터베이스를 만들기 위해 지원서를 수집한다.
설문조사에 참여한 채용 담당자 중 68%는 가짜 채용 공고가 매출에 긍정적인 영향을 미친다고 답했으며, 77%는 가짜 채용 공고가 올라왔을 때 회사 직원의 생산성이 증가했다고 응답했다. 또 관리자의 43%는 유령 채용 공고는 허용될 수 있다고 생각하는 반면, 10%만이 강력하게 비난하고 있었다.
유령 채용 공고 구분법
인력 관리 기관인 BC 매니지먼트는 유령 일자리 현상에 대한 기사를 통해 허위 공고를 구분할 수 있는 몇 가지 기본적인 경고 신호를 다음과 같이 제시했다.
• 채용 과정에서 눈에 띄는 진전 없이 광고가 일반적이거나 오랫동안 반복되는 경우. • 연락 시도 후에도 지원서에 대한 응답이 없는 경우. • 마감일이 없는 경우(예: 지원 마감일이 없거나 시작일이 유동적인 경우). • 다른 지원자의 경험에 대한 정보를 찾을 수 있는 글래스도어와 같은 플랫폼에서 회사의 평판 등급이 낮은 경우.
현실적으로는 허위 구인 공고를 차단할 수 있는 방안이 없다. 그저 이러한 관행을 경계하거나 헌터 응의 제안처럼 규제가 만들어지기를 기다리는 것뿐이다.
서울시가 취약계층 유아에게 양질의 온라인 콘텐츠를 제공하는 ‘서울런 키즈’ 사업을 내년 1년간 시범 운영한다.
서울시 대표 복지 사업인 ‘서울런’을 이용할 수 있는 대상이 취약계층 만 4~5세 유아까지 확대됩니다. 2025년부터 시범운영할 ‘서울런 키즈’는 취약계층 유아의 건강한 발달을 돕기 위해 서울시가 민간업체 6곳과 협력해 제공합니다. 선발된 대상자에게는 양질의 온라인 콘텐츠, 기기, 교재 등이 무료로 지원됩니다. 해당 사업의 지원대상, 모집인원, 신청방법, 선발일정 등을 자세히 알아봅니다.
서울시가 취약계층 만4~5세 유아에게 창의력, 사고력 등을 촉진하는 양질의 온라인 콘텐츠를 제공해 건강한 정서적·신체적 발달을 돕는‘서울런 키즈’ 사업을내년 1년간 시범 운영한다.
서울시는 6개 민간업체(단비교육, 메가스터디교육, 아이스크림에듀, 에누마, 웅진씽크빅, 천재교과서)와 ‘서울런 키즈’ 업무협약을 체결했다. 11월 18일 업무협약식에는 서울시 평생교육국장, 주식회사 케이티(KT), 6개 업체 본부장 등 8명이 참석했다.
취약계층 유아에게 양질의 콘텐츠를 제공해야 할 필요성에 공감한 민간업체의 시범사업 참여로, 서울시에 거주하는 중위소득 60% 이하 가구의 만 4~5세 유아는 내년 1월부터 1년간 6개 민간업체의 유아 맞춤형 온라인 콘텐츠(총 약 10만 개), 기기, 교재 등을 무상으로 지원받는다.
‘서울런 키즈’에 제공되는 온라인 콘텐츠
시범사업에는리틀홈런(아이스크림에듀), 밀크T아이(천재교과서), 스마트올 키즈(웅진씽크빅), 엘리하이키즈(메가스터디교육), 윙크(단비교육), 토도원(에누마) 등의 콘텐츠가 제공된다.
‘서울런 키즈’ 온라인 콘텐츠 예시
콘텐츠 주요 내용으로는 ▲다양한 주제의 동화책을 읽고 한글 익히기 ▲동요를 따라 부르며 몸 움직이기 ▲기본생활 습관 실천하기 ▲영미권 유명 동화책을 통해 재미있게 영어와 친해지기 등이 있다.
참여를 희망하는 가구는 11월 22일부터 12월 6일까지서울런 누리집을 통해 신청할 수 있다. 자격요건을 갖춘 신청인원이 모집인원인 500여 명보다 많은 경우 선착순으로 선발한다.
중위소득 50% 이하 가구는 별도의 서류 준비 없이 누리집에서 실시간 온라인 자격 검증 서비스를 통해 신청할 수 있다. 중위소득 50% 초과 60% 이하 가구는 ①사회보장급여 결정통지서 또는 ②건강보험료 납부확인서, 건강보험 자격확인서, 주민등록등본 중 하나를 제출해야 한다. 문의 사항은서울런 학습지원센터를 이용하면 된다.
‘서울런 키즈’ 선발일정
참여 신청
➜
대상자 선정 발표
➜
콘텐츠 선택
➜
서비스 시작
11.22.~12.6.
12.16. ※변동가능
12.18.~12.20.
2025.1.~
한편 시는 추후 ‘서울런 키즈’ 시범사업의 단기 특화 프로그램으로 YBM넷의 온라인 영어도서관 연계 화상영어 수업인 ‘YBM 영어동화놀이터’ 대상자도 별도 모집해 서비스할 예정이다. 해당 서비스는 아이의 발달 과정과 선호도에 맞춰 애니메이션 동화 학습 후 화상으로 선생님과 수업하는 형식으로 진행된다.
구종원 평생교육국장은 “‘서울런 키즈’ 사업은 유해 미디어의 범람 속에서 아이들이 건강하게 자라날 수 있도록 유익한 미디어 환경을 제공하기 위해 출발했다”라며, “이번 시범사업이 성공적으로 자리 잡아 앞으로 더 많은 아이들에게 안전하고, 질 높은 미디어 학습 기회를 제공하게 되기를 바란다”라고 말했다.
‘서울런 키즈’ 모집안내
○ 지원대상 : 만 4~5세 유아(서울시 거주 중위소득 60% 이하) ※ 시범사업 기간(2025.1.~12.) 기준으로 출생일이 2020.1.1.~2021.12.31.에 해당하는 자 ○ 모집인원 : 500여명 ※ 신청 기간 중 신청인원이 모집인원을 초과할 경우 접수 선착순으로 선발 ○ 신청방법 :서울런 누리집 공지사항을 통해 신청 ○ 시범운영 : 2025.1.~12. (1년) ○ 제공혜택 : 6개 교육업체 중 선택한 1개 교육업체의 온라인 콘텐츠, 기기 등 무상 지원 ○ 교육업체 : 아이스크림에듀, 천재교과서, 웅진씽크빅, 메가스터디교육, 단비교육, 에누마 등 6개 업체 ○ 누리집 :서울런 ○ 문의 : 서울런 학습지원센터 1533-0909
This article explains the new features inPython 3.13, compared to3.12. Python 3.13 was released on October 7, 2024, marking a significant advancement for the language. Many of the most impactful changes occur behind the scenes, so they may take time to notice.
Python 3.13 is setting the stage for future enhancements, particularly in terms ofperformance improvements. For full details, see thechangelog.
Python 3.13 is the latest stable release of the Python programming language, with a mix of changes to the language, the implementation and the standard library. The biggest changes include a newinteractive interpreter, experimental support for running in afree-threaded mode(PEP 703), and aJust-In-Time compiler(PEP 744).
Error messages continue to improve, with tracebacks now highlighted in color by default. Thelocals()builtin now hasdefined semanticsfor changing returning mapping, and type parameters now support values.
The library changes contain removal of deprecated APIs and modules, as well as the usual improvements in user-friendliness and correctness. Several legacy standard library modules have nowbeen removedfollowing their deprecation in Python 3.11 (PEP 594).
Here is a list of major features and improved modules.
·Improved REPL
· Free Threading Cpython
· An Experimental just-in-time (JIT)
· Improved Error Messages
· Copy’s Replace
· Support for Mobile Platforms
Improved REPL
Python now uses a newinteractiveshell by default, based on code from thePyPy project. When the user starts theREPLfrom an interactive terminal, the following new features are now supported:
Multiline editing with history preservation.
Direct support for REPL-specific commands like help, exit, and quit, without the need to call them as functions.
Interactive help browsing using F1 with a separate command history.
History browsing using F2 that skips output as well as the>>>and…prompts.
“Paste mode” with F3 that makes pasting larger blocks of code easier (press F3 again to return to the regular prompt).
Free Threading Cpython
CPython now has experimental support for running in a free-threaded mode, with theglobal interpreter lock(GIL) disabled. This is an experimental feature and therefore is not enabled by default. The free-threaded mode requires a different executable, usually called python3.13t or python3.13t.exe. Pre-built binaries marked asfree-threadedcan be installed as part of the officialWindowsandmacOSinstallers, or CPython can be built from source with the— disable-giloption.
An Experimental just-in-time (JIT)
When CPython is configured and built using the — enable-experimental-jit option, a just-in-time (JIT) compiler is added which may speed up some Python programs. On Windows, use PCbuild/build.bat — experimental-jit to enable the JIT or — experimental-jit-interpreter to enable the Tier 2 interpreter. Build requirements and further supporting informationare contained atTools/jit/README.md.
Improved Error Messages
The interpreter now uses color by default when displaying tracebacks in the terminal. This featurecan be controlledvia the newPYTHON_COLORSenvironment variable as well as the canonicalNO_COLORandFORCE_COLORenvironment variables. (Contributed by Pablo Galindo Salgado ingh-112730.)
The error message now tries to suggest the correct keyword argument when an incorrect keyword argument is passed to a function.
# Incorrect usage of the built-in sorted() function
sorted([3, 1, 2], reversed=True)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
sorted([3, 1, 2], reversed=True)
~~~~~~~~~~~~~~~~~~~~~~~^^^^^^^^
TypeError: sorted() got an unexpected keyword argument 'reversed'. Did you mean 'reverse'?
Copy’s Replace
The newreplace()function and thereplace protocolmake creating modified copies of objects much simpler. This is especially useful when working with immutable objects. The following types support thereplace()function and implement the replace protocol:
PEP 730: iOS is now aPEP 11supported platform, with the arm64-apple-ios and arm64-apple-ios-simulator targets at tier 3 (iPhone and iPad devices released after 2013 and the Xcode iOS simulator running on Apple silicon hardware, respectively). x86_64-apple-ios-simulator (the Xcode iOS simulator running on older x86_64 hardware) is not a tier 3 supported platform, but will have best-effort support. (PEP written and implementation contributed by Russell Keith-Magee ingh-114099.)
PEP 738: Android is now aPEP 11supported platform, with the aarch64-linux-android and x86_64-linux-android targets at tier 3. The 32-bit targets arm-linux-androideabi and i686-linux-android are not tier 3 supported platforms, but will have best-effort support. (PEP written and implementation contributed by Malcolm Smith ingh-116622.)
PyQt5와 requests 및 BeautifulSoup를 이용해 URL을 입력하고, 해당 웹 페이지의 내용을 크롤링하여 보여주는 기본 프로그램.
입력한 URL의 HTML 내용과 크롤링된 특정 텍스트 내용을 보여주는 두 개의 영역
import sys
import requests
from bs4 import BeautifulSoup
from PyQt5.QtWidgets import QApplication, QWidget, QVBoxLayout, QLabel, QLineEdit, QPushButton, QScrollArea, QTextBrowser, QTextEdit
from PyQt5.QtCore import Qt
class WebCrawlerApp(QWidget):
def __init__(self):
super().__init__()
self.initUI()
def initUI(self):
# 창 설정
self.setWindowTitle("URL Web Crawler")
self.setGeometry(300, 300, 800, 600)
# 메인 레이아웃 설정
layout = QVBoxLayout()
# URL 입력창 및 버튼 추가
self.url_input = QLineEdit(self)
self.url_input.setPlaceholderText("Enter URL here...")
layout.addWidget(self.url_input)
self.submit_button = QPushButton("Submit", self)
self.submit_button.clicked.connect(self.fetch_web_content)
layout.addWidget(self.submit_button)
# HTML 내용 표시 (링크 지원을 위해 QTextBrowser 사용)
self.html_label = QLabel("Page HTML Content:")
layout.addWidget(self.html_label)
self.html_content = QTextBrowser(self)
self.html_content.setOpenExternalLinks(False) # QTextBrowser 내부에서 링크 클릭 이벤트를 처리
self.html_content.anchorClicked.connect(self.handle_link_click)
html_scroll = QScrollArea(self)
html_scroll.setWidgetResizable(True)
html_scroll.setWidget(self.html_content)
layout.addWidget(html_scroll)
# 크롤링된 내용을 보여줄 텍스트 창
self.crawl_label = QLabel("Crawled Data:")
layout.addWidget(self.crawl_label)
self.crawled_content = QTextEdit(self)
self.crawled_content.setReadOnly(True)
crawl_scroll = QScrollArea(self)
crawl_scroll.setWidgetResizable(True)
crawl_scroll.setWidget(self.crawled_content)
layout.addWidget(crawl_scroll)
# 레이아웃 설정
self.setLayout(layout)
def fetch_web_content(self):
# URL 가져오기
url = self.url_input.text().strip()
if not url:
self.html_content.setText("Please enter a valid URL.")
return
try:
# 웹 페이지 요청 및 파싱
response = requests.get(url)
response.raise_for_status()
html_text = response.text
# HTML 내용을 보여줌
self.html_content.setHtml(html_text)
# BeautifulSoup으로 HTML 파싱
soup = BeautifulSoup(html_text, 'html.parser')
# 특정 태그 내용 크롤링 예시 (모든 <p> 태그 내용)
paragraphs = soup.find_all('p')
crawled_data = "\n\n".join([p.get_text(strip=True) for p in paragraphs])
# 크롤링된 내용 표시
if crawled_data:
self.crawled_content.setText(crawled_data)
else:
self.crawled_content.setText("No <p> tags found on the page.")
except requests.exceptions.RequestException as e:
self.html_content.setText(f"Error fetching the URL: {e}")
self.crawled_content.setText("")
def handle_link_click(self, url):
# 링크를 클릭하면 URL 입력창에 설정하고 자동으로 Submit
self.url_input.setText(url.toString())
self.fetch_web_content()
# 애플리케이션 실행
if __name__ == "__main__":
app = QApplication(sys.argv)
window = WebCrawlerApp()
window.show()
sys.exit(app.exec_())