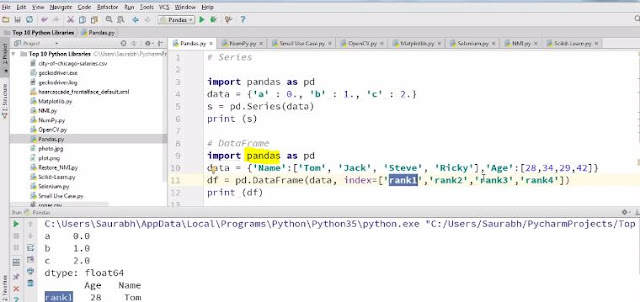
1. Pandas Pandas is a software library written for the python programming language for data manipulation and analysis. Pandas is well suited for many different kinds of data:
Tabular data with heterogeneously-types columns.
Ordered and unordered time series data.
Arbitrary matrix data with row and column labels.
Any other form of observational / statistical data sets.
The data actually need not be labeled at all to be placed into a pandas data structure.
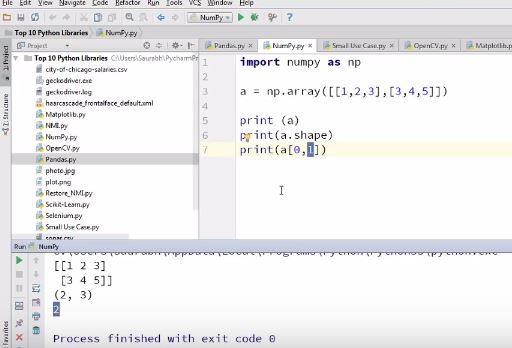
2. NumPy Numpy is the core library for scientific computing in Python. It provides a high-performance multidimensional array object, and tools for working with these arrays.
3. Matplotlib
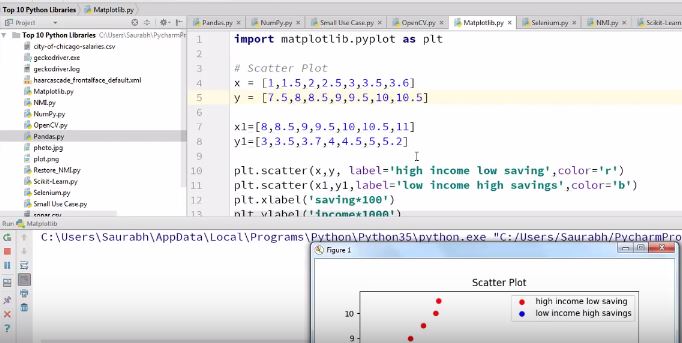
Matplotlib is a Python package used for 2D graphics.
Bar graph
Histograms
Scatter Plot
Pie Plot
Hexagonal Bin Plot
Area Plot
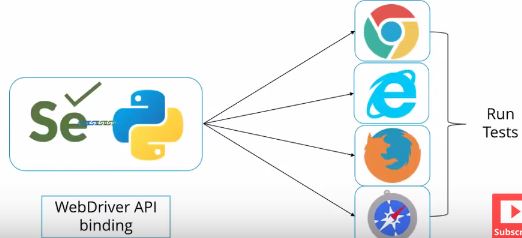
4. Selenium
The selenium package is used to automate web browser interaction from Python.
5. OpenCV
OpenCV- Python is a library of Python designed to solve computer vision problems.
6. SciPy
Scipy is a free and open-source Python library used for scientific computing and technical computing.
7. Scikit-Learn
Scikit-learn (formerly scikits.learn) is a free software machine learning library for the Python programming language. It features various classification, regression and clustering algorithms.
8. PySpark
The Spark Python API (PySpark) exposes the Spark programming model to Python.
9. Django
Diango is a Python web framework. A framework provides a structure and common methods to make the life of a web application developer much easier for building flexible, scalable and maintainable web applications
Django is a high-level and has a MVC-MVT styled architecture.
Django web framework is written on quick and powerful Python language.
Django has a open-source collection of libraries for building a fully functioning web application.
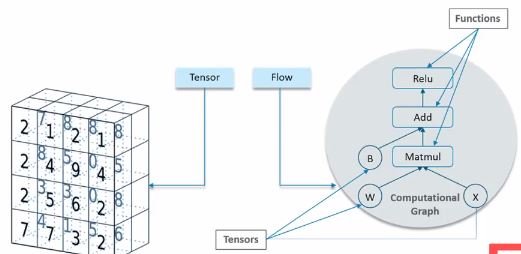
10. Tensor Flow
TensorFlow is a Python library used to implement deep networks. In TensorFlow, computation is approached as a dataflow graph.
러스트 재단에서 개발되고 있는 메모리 안전성과 성능 및 편의성에 중점을 둔 프로그래밍 언어. 가비지 컬렉터 없이 메모리 안전성을 제공하는 대표적인 언어다. C++의 대체재로써 등장했다.
모질라 재단에서 2010년 7월 7일에 처음 발표했으며, 2015년 5월 15일에 안정 버전이 정식 발표된 이후, 2021년 2월부터는 러스트 재단으로 분리되어 AWS, Google, 화웨이, MS, 모질라 재단을 초기 회원사로 발족했다.
이 언어를 대표하는 키워드 몇 개를 나열해보면 안전성, 속도, 병렬 프로그래밍, 함수형 프로그래밍, 시스템 프로그래밍이 있다. Go보다는 반 년 늦게 나왔지만 그나마 비슷한 시기에 등장했다는 점과 두 언어 모두 C/C++를 서로 다른 방향에서 대체하려 한다는 점 때문에 라이벌 관계로 엮이기도 한다.
온라인상으로 표준 라이브러리 기반의 코드를 실행해볼 수 있다. #
Rust의 비공식 마스코트도 있는데, 이름은 페리스(Ferris)다. 밝은 주황색의 게 모양을 하고 있으며, 러스트 관련 커뮤니티나 미디어에서 자주 등장한다. 또한 이 페리스 때문에 Rust 개발자는 스스로를 Rustacean이라고 자칭한다.
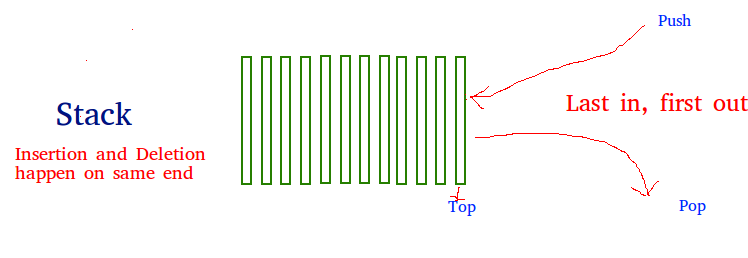
Astackis a linear data structure that stores items in aLast-In/First-Out (LIFO)or First-In/Last-Out (FILO) manner. In stack, a new element is added at one end and an element is removed from that end only. The insert and delete operations are often called push and pop.
The functions associated with stack are:
empty()– Returns whether the stack is empty – Time Complexity: O(1)
size()– Returns the size of the stack – Time Complexity: O(1)
top() / peek()– Returns a reference to the topmost element of the stack – Time Complexity: O(1)
push(a)– Inserts the element ‘a’ at the top of the stack – Time Complexity: O(1)
pop()– Deletes the topmost element of the stack – Time Complexity: O(1)
Implementation:
There are various ways from which a stack can be implemented in Python. This article covers the implementation of a stack using data structures and modules from the Python library. Stack in Python can be implemented using the following ways:
list
Collections.deque
queue.LifoQueue
# Python program to
# demonstrate stack implementation
# using list
stack = []
# append() function to push
# element in the stack
stack.append('a')
stack.append('b')
stack.append('c')
print('Initial stack')
print(stack)
# pop() function to pop
# element from stack in
# LIFO order
print('\nElements popped from stack:')
print(stack.pop())
print(stack.pop())
print(stack.pop())
print('\nStack after elements are popped:')
print(stack)
# uncommenting print(stack.pop())
# will cause an IndexError
# as the stack is now empty
지난 9월 5일, 개인정보보호위원회(이하 ‘개인정보위’)는 보도자료를 통해 국무회의에서 「개인정보 보호법」 시행령 개정안이 의결됨에 따라 지난 3월 14일 공포된 개인정보 보호법과 후속 개정 시행령이 9월 15일부터 시행 예정임을 밝히면서 그 주요 내용을 공개하였습니다.
개인정보위는 이번 개인정보 보호법과 후속 시행령 개정으로 국민의 개인정보를 처리하는 과정에서 준수해야 할 사항에 많은 변화가 예상되므로 기업 및 공공기관 등의 개인정보처리자에게 개정사항에 대한 꼼꼼한 확인을 당부하기도 하였는데요.
이번 포스팅에서는 개인정보 보호법의 개정 경과를 살펴보고, 개인정보 보호법의 개정 주요 내용에 대해 알아보도록 하겠습니다.
개인정보 보호법 개정 경과
네이버의 개인정보보호 공식 블로그는 개인정보 및 프라이버시와 관련해서 이용자 여러분과 소통하는 채널인 만큼, 개인정보의 근간이 되는 개인정보 보호법 개정에 관한 소식을 중요한 주제로 다루어 포스팅을 통해서 몇 차례 관련 소식을 전해드리기도 했는데요.