
Ibis는 모든 쿼리 엔진에서 실행되는 Python 데이터프레임 API를 정의합니다. 현재 20개 이상의 백엔드가 있는 모든 백엔드 데이터 플랫폼의 프런트엔드입니다. 이를 통해 Ibis는 연결된 백엔드만큼 뛰어난 성능을 일관된 사용자 경험과 함께 제공할 수 있습니다.
Why Ibis? – Ibis
the portable Python dataframe library
ibis-project.org
Why Ibis?
Ibis defines a Python dataframe API that executes on any query engine – the frontend for any backend data platform, with 20+ backends today. This allows Ibis to have excellent performance – as good as the backend it is connected to – with a consistent user experience.
What is Ibis?
Ibis is the portable Python dataframe library.
We can demonstrate this with a simple example on a few local query engines:
import ibis
ibis.options.interactive = True1con = ibis.connect("duckdb://")
t = con.read_parquet("penguins.parquet")
t.limit(3)┏━━━━━━━━━┳━━━━━━━━━━━┳━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┓
┃ species ┃ island ┃ bill_length_mm ┃ bill_depth_mm ┃ flipper_length_mm ┃ body_mass_g ┃ sex ┃ year ┃
┡━━━━━━━━━╇━━━━━━━━━━━╇━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━┩
│ string │ string │ float64 │ float64 │ int64 │ int64 │ string │ int64 │
├─────────┼───────────┼────────────────┼───────────────┼───────────────────┼─────────────┼────────┼───────┤
│ Adelie │ Torgersen │ 39.1 │ 18.7 │ 181 │ 3750 │ male │ 2007 │
│ Adelie │ Torgersen │ 39.5 │ 17.4 │ 186 │ 3800 │ female │ 2007 │
│ Adelie │ Torgersen │ 40.3 │ 18.0 │ 195 │ 3250 │ female │ 2007 │
└─────────┴───────────┴────────────────┴───────────────┴───────────────────┴─────────────┴────────┴───────┘
t.group_by(["species", "island"]).agg(count=t.count()).order_by("count")┏━━━━━━━━━━━┳━━━━━━━━━━━┳━━━━━━━┓
┃ species ┃ island ┃ count ┃
┡━━━━━━━━━━━╇━━━━━━━━━━━╇━━━━━━━┩
│ string │ string │ int64 │
├───────────┼───────────┼───────┤
│ Adelie │ Biscoe │ 44 │
│ Adelie │ Torgersen │ 52 │
│ Adelie │ Dream │ 56 │
│ Chinstrap │ Dream │ 68 │
│ Gentoo │ Biscoe │ 124 │
└───────────┴───────────┴───────┘
Who is Ibis for?
Ibis is for data engineers, data analysts, and data scientists (or any title that needs to work with data!) to use directly with their data platform(s) of choice. It also has benefits for data platforms, organizations, and library developers.
Ibis for practitioners
You can use Ibis at any stage of your data workflow, no matter your role.
Data engineers can use Ibis to:
- write and maintain complex ETL/ELT jobs
- replace fragile SQL string pipelines with a robust Python API
- replace PySpark with a more Pythonic API that supports Spark and many other backends
Data analysts can use Ibis to:
- use Ibis interactive mode for rapid exploration
- perform rapid exploratory data analysis using interactive mode
- create end-to-end analytics workflows
- work in a general-purpose, yet easy to learn, programming language without the need for formatting SQL strings
Data scientists can use Ibis to:
- extract a sample of data for local iteration with a fast local backend
- prototype with the same API that will be used in production
- preprocess and feature engineer data before training a machine learning model
Ibis for data platforms
Data platforms can use Ibis to quickly bring a fully-featured Python dataframe library with minimal effort to their platform. In addition to a great Python dataframe experience for their users, they also get integrations into the broader Python and ML ecosystem.
Often, data platforms evolve to support Python in some sequence like:
- Develop a fast query engine with a SQL frontend
- Gain popularity and need to support Python for data science and ML use cases
- Develop a bespoke pandas or PySpark-like dataframe library and ML integrations
This third step is where Ibis comes in. Instead of spending a lot of time and money developing a bespoke Python dataframe library, you can create an Ibis backend for your data platform in as little as four hours for an experienced Ibis developer or, more typically, on the order of one or two months for a new contributor.
Ibis for organizations
Organizations can use Ibis to standardize the interface for SQL and Python data practitioners. It also allows organizations to:
- transfer data between systems
- transform, analyze, and prepare data where it lives
- benchmark your workload(s) across data systems using the same code
- mix SQL and Python code seamlessly, with all the benefits of a general-purpose programming language, type checking, and expression validation
Ibis for library developers
Python developers creating libraries can use Ibis to:
- instantly support 20+ data backends
- instantly support pandas, PyArrow, and Polars objects
- read and write from all common file formats (depending on the backend)
- trace column-level lineage through Ibis expressions
- compile Ibis expressions to SQL or Substrait
- perform cross-dialect SQL transpilation (powered by SQLGlot)
How does Ibis work?
Most Python dataframes are tightly coupled to their execution engine. And many databases only support SQL, with no Python API. Ibis solves this problem by providing a common API for data manipulation in Python, and compiling that API into the backend’s native language. This means you can learn a single API and use it across any supported backend (execution engine).
Ibis broadly supports two types of backend:
- SQL-generating backends
- DataFrame-generating backends
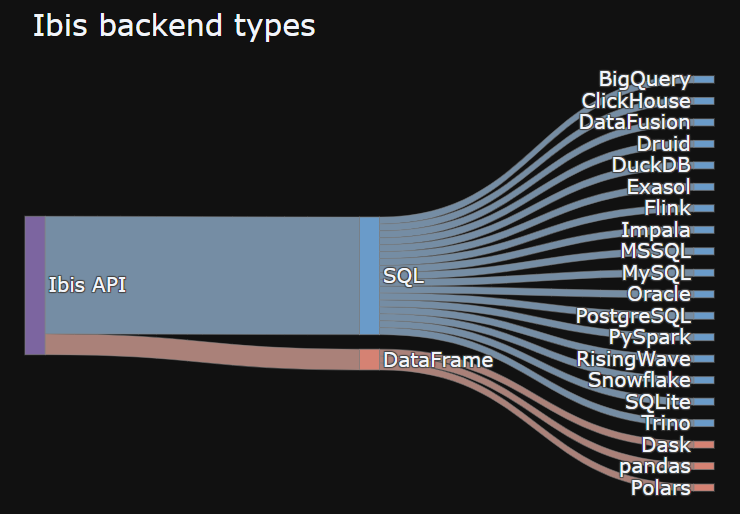
As you can see, most backends generate SQL. Ibis uses SQLGlot to transform Ibis expressions into SQL strings. You can also use the .sql() methods to mix in SQL strings, compiling them to Ibis expressions.
While portability with Ibis isn’t perfect, commonalities across backends and SQL dialects combined with years of engineering effort produce a full-featured and robust framework for data manipulation in Python.
In the long-term, we aim for a standard query plan Intermediate Representation (IR) like Substrait to simplify this further.
Python + SQL: better together
For most backends, Ibis works by compiling Python expressions into SQL:
g = t.group_by(["species", "island"]).agg(count=t.count()).order_by("count")
ibis.to_sql(g)SELECT
*
FROM (
SELECT
`t0`.`species`,
`t0`.`island`,
COUNT(*) AS `count`
FROM `ibis_read_parquet_pp72u4gfkjcdpeqcawnpbt6sqq` AS `t0`
GROUP BY
1,
2
) AS `t1`
ORDER BY
`t1`.`count` ASC NULLS LASTYou can mix and match Python and SQL code:
sql = """
SELECT
species,
island,
COUNT(*) AS count
FROM penguins
GROUP BY species, island
""".strip()con = ibis.connect("duckdb://")
t = con.read_parquet("penguins.parquet")
g = t.alias("penguins").sql(sql)
g┏━━━━━━━━━━━┳━━━━━━━━━━━┳━━━━━━━┓
┃ species ┃ island ┃ count ┃
┡━━━━━━━━━━━╇━━━━━━━━━━━╇━━━━━━━┩
│ string │ string │ int64 │
├───────────┼───────────┼───────┤
│ Adelie │ Torgersen │ 52 │
│ Adelie │ Biscoe │ 44 │
│ Adelie │ Dream │ 56 │
│ Gentoo │ Biscoe │ 124 │
│ Chinstrap │ Dream │ 68 │
└───────────┴───────────┴───────┘
g.order_by("count")┏━━━━━━━━━━━┳━━━━━━━━━━━┳━━━━━━━┓
┃ species ┃ island ┃ count ┃
┡━━━━━━━━━━━╇━━━━━━━━━━━╇━━━━━━━┩
│ string │ string │ int64 │
├───────────┼───────────┼───────┤
│ Adelie │ Biscoe │ 44 │
│ Adelie │ Torgersen │ 52 │
│ Adelie │ Dream │ 56 │
│ Chinstrap │ Dream │ 68 │
│ Gentoo │ Biscoe │ 124 │
└───────────┴───────────┴───────┘
This allows you to combine the flexibility of Python with the scale and performance of modern SQL.
Scaling up and out
Out of the box, Ibis offers a great local experience for working with many file formats. You can scale up with DuckDB (the default backend) or choose from other great options like Polars and DataFusion to work locally with large datasets. Once you hit scaling issues on a local machine, you can continue scaling up with a larger machine in the cloud using the same backend and same code.
If you hit scaling issues on a large single-node machine, you can switch to a distributed backend like PySpark, BigQuery, or Trino by simply changing your connection string.
Stream-batch unification
As of Ibis 8.0, the first stream processing backends have been added. Since these systems tend to support SQL, we can with minimal changes to Ibis support both batch and streaming workloads with a single API. We aim to further unify the batch and streaming paradigms going forward.
Ecosystem
Ibis is part of a larger ecosystem of Python data tools. It is designed to work well with other tools in this ecosystem, and we continue to make it easier to use Ibis with other tools over time.
Ibis already works with other Python dataframes like:
Ibis already works well with visualization libraries like:
Ibis already works well with dashboarding libraries like:
Ibis already works well with machine learning libraries like:
Supported backends
You can install Ibis and a supported backend with pip, conda, mamba, or pixi.
- BigQuery
- ClickHouse
- DataFusion
- Druid
- DuckDB
- Exasol
- Flink
- Impala
- MSSQL
- MySQL
- Oracle
- Polars
- PostgreSQL
- PySpark
- RisingWave
- Snowflake
- SQLite
- Trino
Install with the bigquery extra:
pip install 'ibis-framework[bigquery]'Connect using ibis.bigquery.connect.
Note that the ibis-framework package is not the same as the ibis package in PyPI. These two libraries cannot coexist in the same Python environment, as they are both imported with the ibis module name.
See the backend support matrix for details on operations supported. Open a feature request if you’d like to see support for an operation in a given backend. If the backend supports it, we’ll do our best to add it quickly!
Community
Community discussions primarily take place on GitHub and Zulip.
Getting started
If you’re interested in trying Ibis we recommend the getting started tutorial.
'프로그래밍 > Python' 카테고리의 다른 글
| [python] 2차 방정식 (0) | 2024.09.10 |
|---|---|
| [python] html table을 Markdown으로 변경하기. (0) | 2024.09.04 |
| [python] Working With Mathematical Operations and Permutations. 수학적 연산과 순열 (0) | 2024.08.23 |
| [python] 폴더 안의 파일들 이름의 공백 또는 - 를 언더바로 변경하는 프로그램 (0) | 2024.08.23 |
| [python] Working With The Operating System (0) | 2024.08.13 |

