# 파이썬 컴파일 경로가 달라서 현재 폴더의 이미지를 호출하지 못할때 작업디렉토리를 변경한다.
import os
from pathlib import Path
# src 상위 폴더를 실행폴더로 지정하려고 한다.
###real_path = Path(__file__).parent.parent
real_path = Path(__file__).parent
print(real_path)
#작업 디렉토리 변경
os.chdir(real_path)
"""_summary_
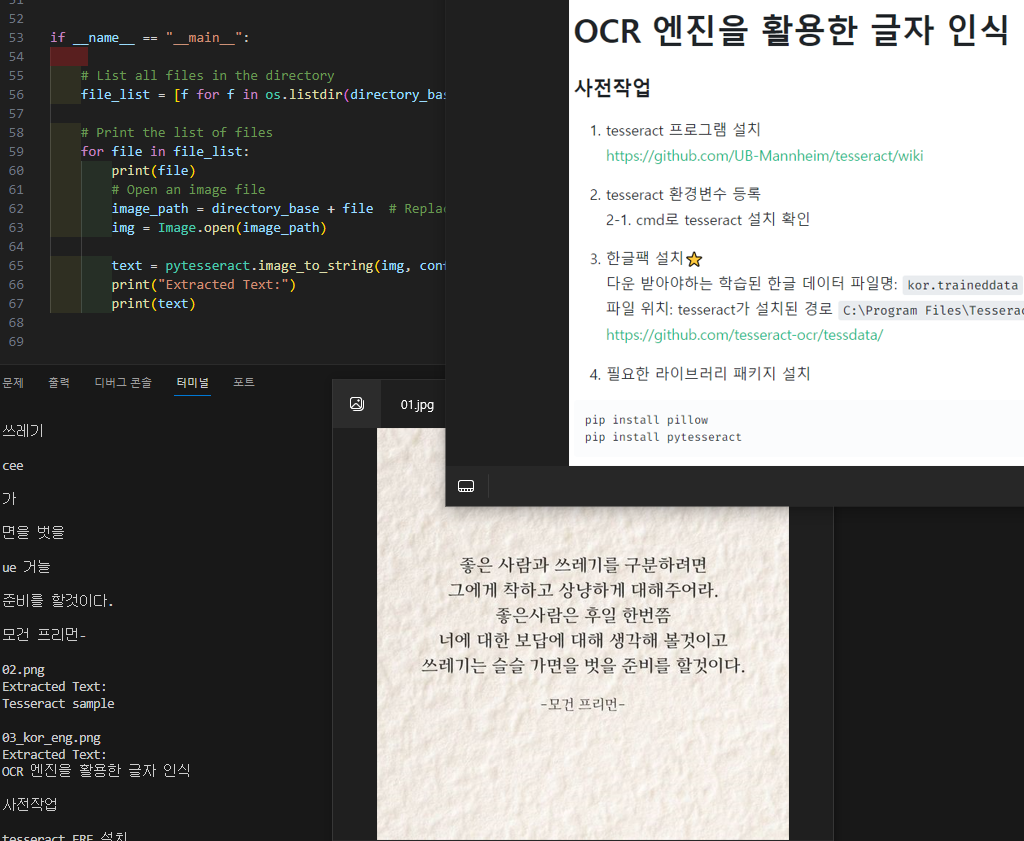
pip install pillow
pip install pytesseract
다운 받아야하는 학습된 한글 데이터 파일명: kor.traineddata
파일 위치: tesseract가 설치된 경로 C:\Program Files\Tesseract-OCR\tessdata
"""
from PIL import Image
import pytesseract
import cv2
import matplotlib.pyplot as plt
pytesseract.pytesseract.tesseract_cmd = r'C:\Program Files\Tesseract-OCR\tesseract.exe'
config = ('-l kor+eng --oem 3 --psm 11')
#config = ('-l kor+eng')
directory_base = str(real_path)+"./img/" # 경로object를 문자열로 변경해서 합친다.
# Open an image file
image_path = directory_base+"03_kor_eng.png" # Replace with your image file path
img = Image.open(image_path)
# Use Tesseract to extract text
text = pytesseract.image_to_string(img, config=config)
print("Extracted Text:" + text)
image = cv2.imread(image_path)
rgb_image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
plt.imshow(rgb_image)
# use Tesseract to OCR the image
# text = pytesseract.image_to_string(rgb_image, lang='kor+eng')
text = pytesseract.image_to_string(rgb_image, config=config)
print(text)
if __name__ == "__main__":
# List all files in the directory
file_list = [f for f in os.listdir(directory_base) if os.path.isfile(os.path.join(directory_base, f))]
# Print the list of files
for file in file_list:
print(file)
# Open an image file
image_path = directory_base + file # Replace with your image file path
img = Image.open(image_path)
text = pytesseract.image_to_string(img, config=config)
print("Extracted Text:")
print(text)
다운 받아야하는 학습된 한글 데이터 파일명:kor.traineddata 파일 위치: tesseract가 설치된 경로C:\Program Files\Tesseract-OCR\tessdata
*** 설치 할때 언어팩 선택
pytesseract 0.3.10
Python-tesseract is an optical character recognition (OCR) tool for python. That is, it will recognize and “read” the text embedded in images.
Python-tesseract is a wrapper forGoogle’s Tesseract-OCR Engine. It is also useful as a stand-alone invocation script to tesseract, as it can read all image types supported by the Pillow and Leptonica imaging libraries, including jpeg, png, gif, bmp, tiff, and others. Additionally, if used as a script, Python-tesseract will print the recognized text instead of writing it to a file.
USAGE
Quickstart
Note: Test images are located in thetests/datafolder of the Git repo.
Library usage:
from PIL import Image
import pytesseract
# If you don't have tesseract executable in your PATH, include the following:
pytesseract.pytesseract.tesseract_cmd = r'<full_path_to_your_tesseract_executable>'
# Example tesseract_cmd = r'C:\Program Files (x86)\Tesseract-OCR\tesseract'
# Simple image to string
print(pytesseract.image_to_string(Image.open('test.png')))
# In order to bypass the image conversions of pytesseract, just use relative or absolute image path
# NOTE: In this case you should provide tesseract supported images or tesseract will return error
print(pytesseract.image_to_string('test.png'))
# List of available languages
print(pytesseract.get_languages(config=''))
# French text image to string
print(pytesseract.image_to_string(Image.open('test-european.jpg'), lang='fra'))
# Batch processing with a single file containing the list of multiple image file paths
print(pytesseract.image_to_string('images.txt'))
# Timeout/terminate the tesseract job after a period of time
try:
print(pytesseract.image_to_string('test.jpg', timeout=2)) # Timeout after 2 seconds
print(pytesseract.image_to_string('test.jpg', timeout=0.5)) # Timeout after half a second
except RuntimeError as timeout_error:
# Tesseract processing is terminated
pass
# Get bounding box estimates
print(pytesseract.image_to_boxes(Image.open('test.png')))
# Get verbose data including boxes, confidences, line and page numbers
print(pytesseract.image_to_data(Image.open('test.png')))
# Get information about orientation and script detection
print(pytesseract.image_to_osd(Image.open('test.png')))
# Get a searchable PDF
pdf = pytesseract.image_to_pdf_or_hocr('test.png', extension='pdf')
with open('test.pdf', 'w+b') as f:
f.write(pdf) # pdf type is bytes by default
# Get HOCR output
hocr = pytesseract.image_to_pdf_or_hocr('test.png', extension='hocr')
# Get ALTO XML output
xml = pytesseract.image_to_alto_xml('test.png')
Support for OpenCV image/NumPy array objects
import cv2
img_cv = cv2.imread(r'/<path_to_image>/digits.png')
# By default OpenCV stores images in BGR format and since pytesseract assumes RGB format,
# we need to convert from BGR to RGB format/mode:
img_rgb = cv2.cvtColor(img_cv, cv2.COLOR_BGR2RGB)
print(pytesseract.image_to_string(img_rgb))
# OR
img_rgb = Image.frombytes('RGB', img_cv.shape[:2], img_cv, 'raw', 'BGR', 0, 0)
print(pytesseract.image_to_string(img_rgb))
If you need custom configuration likeoem/psm, use theconfigkeyword.
# Example of adding any additional options
custom_oem_psm_config = r'--oem 3 --psm 6'
pytesseract.image_to_string(image, config=custom_oem_psm_config)
# Example of using pre-defined tesseract config file with options
cfg_filename = 'words'
pytesseract.run_and_get_output(image, extension='txt', config=cfg_filename)
Add the following config, if you have tessdata error like: “Error opening data file…”
# Example config: r'--tessdata-dir "C:\Program Files (x86)\Tesseract-OCR\tessdata"'
# It's important to add double quotes around the dir path.
tessdata_dir_config = r'--tessdata-dir "<replace_with_your_tessdata_dir_path>"'
pytesseract.image_to_string(image, lang='chi_sim', config=tessdata_dir_config)
Functions
get_languagesReturns all currently supported languages by Tesseract OCR.
get_tesseract_versionReturns the Tesseract version installed in the system.
image_to_stringReturns unmodified output as string from Tesseract OCR processing
image_to_boxesReturns result containing recognized characters and their box boundaries
image_to_dataReturns result containing box boundaries, confidences, and other information. Requires Tesseract 3.05+. For more information, please check theTesseract TSV documentation
image_to_osdReturns result containing information about orientation and script detection.
image_to_alto_xmlReturns result in the form of Tesseract’s ALTO XML format.
run_and_get_outputReturns the raw output from Tesseract OCR. Gives a bit more control over the parameters that are sent to tesseract.
imageObject or String - PIL Image/NumPy array or file path of the image to be processed by Tesseract. If you pass object instead of file path, pytesseract will implicitly convert the image toRGB mode.
langString - Tesseract language code string. Defaults toengif not specified! Example for multiple languages:lang='eng+fra'
configString - Anyadditional custom configuration flagsthat are not available via the pytesseract function. For example:config='--psm6'
niceInteger - modifies the processor priority for the Tesseract run. Not supported on Windows. Nice adjusts the niceness of unix-like processes.
output_typeClass attribute - specifies the type of the output, defaults tostring. For the full list of all supported types, please check the definition ofpytesseract.Outputclass.
timeoutInteger or Float - duration in seconds for the OCR processing, after which, pytesseract will terminate and raise RuntimeError.
pandas_configDict - only for theOutput.DATAFRAMEtype. Dictionary with custom arguments forpandas.read_csv. Allows you to customize the output ofimage_to_data.
CLI usage:
pytesseract [-l lang] image_file
INSTALLATION
Prerequisites:
Python-tesseract requires Python 3.6+
You will need the Python Imaging Library (PIL) (or thePillowfork). Under Debian/Ubuntu, this is the packagepython-imagingorpython3-imaging.
InstallGoogle Tesseract OCR(additional info how to install the engine on Linux, Mac OSX and Windows). You must be able to invoke the tesseract command astesseract. If this isn’t the case, for example because tesseract isn’t in your PATH, you will have to change the “tesseract_cmd” variablepytesseract.pytesseract.tesseract_cmd. Under Debian/Ubuntu you can use the packagetesseract-ocr. For Mac OS users. please install homebrew packagetesseract.
Note:In some rare cases, you might need to additionally installtessconfigsandconfigsfromtesseract-ocr/tessconfigsif the OS specific package doesn’t include them.
에듀테크 시대 새로운 공부문화를 창조하는 ㈜바풀은 전 세계 최초로 사진 속 수학문제를 인식해 같은 문제와 유사 문제를 찾아 풀이와 답변을 제공하는 ‘자동답변’ 기술을 개발했다고 26일 밝혔다.
㈜바풀은 바로풀기 서비스를 통해 모르는 문제가 생기면 스마트폰으로 사진을 찍어 질문하고 답변 받는 무료 공부 Q&A서비스를 운영 중이다. 이번에 개발한 ‘자동답변’ 에듀테크 기술은 지난 6년 간 바로풀기 서비스를 통해 구축한 400만 개 가운데 답변이 달린 100만 개의 DB를 검토하여 똑같은 질문을 찾아서 풀이와 답변을 보여주는 기술이다.
똑같은 질문이 없을 경우, 수학문제의 수식과 텍스트(한국·영어)를 인식해서 유사한 질문의 답변을 제공하는 방식으로 문제풀이를 도와준다.
세계 최초로 개발한 ‘자동답변’ 기술은 세 가지 기술이 융합되어 얻어진 결과다.
먼저 ‘사진 후처리 기술’은 사용자가 촬영한 수학 문제로부터 각종 노이즈를 제거하고, 회전각과 비틀림 각을 보정해 문제 사진이 수평이 되도록 만든다.
이렇게 보정된 사진은 20여 단계로 구성된 독자적인 OCR(OpticalCharacterReader/Recognition, 광학적 문자 판독) 기술을 통해 사진 속의 텍스트와 수식을 분리하고 이를 메타 정보로 기록한다.
마지막으로 6년간의 서비스에서 얻어진 각 학년별 수학 단원 및 개념 맵을 활용함으로써 DB로부터 해당 문제의 답변, 그리고 사용자에게 도움이 될 수 있는 유사 문제를 제공한다.
지금까지의 OCR기술은 한글보다 상대적으로 쉬운 언어인 영문 환경에 한해서만 그 기능을 수행할 수 있었고, 수학 문제에서는 수식으로만 이루어진 간단한 계산문제에 대해서만 풀이를 제공하는 수준이었으나, ㈜바풀은 세계 최초로 한글과 수식이 혼합된 환경에서도 그 둘을 각각 분리하여 사진 형태의 문제를 분석해 3초 정도의 시간이면 답변을 찾아준다.
㈜바풀의 ‘자동 답변’기술을 통해 얻어진 학생의 정보는 ‘KnowledgeTracing’이 가능하며, 학생의 학습이력 관리 및 수준에 맞는 맞춤 강의와 선생님을 추천할 수 있다. 또한, 문제를 바탕으로 메타 콘셉트 데이터를 구축해서 문제 하나가 갖고 있는 여러 개념들을 묶어주고 분류할 수 있게 되어 학생들에게 유용한 정보를 제공할 수 있게 된다.
바풀 김영재 CTO는 “바풀의 ‘자동답변’ 신기술을 통해 많은 학생들이 수학을 포기하지 않고 공부에 대한 재미를 느꼈으면 좋겠다”며 “㈜바풀은 교육과 IT를 접목한 에듀테크 신기술로 모든 학생들이 동등한 교육환경 속에서 양질의 교육을 경험할 수 있도록 노력하겠다”고 전했다.