https://uxdesign.cc/58-rules-for-stunning-and-effective-user-interface-design-ea4b93f931f6
58 rules for beautiful UI design
The right UI can elevate an application from functional to unforgettable, making the difference between a user who engages once and one…
uxdesign.cc
Crafted to be your ultimate roadmap in the journey of UI design. Whether you are a seasoned designer looking to refresh your approach or a novice eager to learn the ropes, these rules are tailored to help you create interfaces that are not just visually appealing but also intuitively functional. To navigate this complex terrain, I have compiled 58 rules across eight categories, collectively forming the “Elegance Formula” for user interface design.

🫀 Empathy: There is no universal concept of beauty; only when you truly understand your target audience can you create a design that is appealing to them.
🖼️ Layout: The layout is the canvas of your interface; it should guide the user’s eye effortlessly, creating a seamless flow that intuitively connects each element.
🎟 Essentialism: Embrace simplicity; every element in your design should serve a purpose, as clutter can obscure the message and hinder the user experience.
🧭 Guidance: Design should not just please the eye but also lead the user, providing clear pathways and cues for what they should do next.
💎 Aesthetics: Aesthetics go beyond mere appearance; they encapsulate the feel of the design, creating an environment that resonates emotionally with the user.
🛸 Novelty: Innovative designs capture attention, but the true art lies in balancing novelty with familiarity, ensuring users feel intrigued yet comfortable.
🎛 Consistency: Consistency in design breeds familiarity; it ensures the user feels at home across various parts of your interface, building trust and ease of use.
🕹 Engagement: An engaging design is like a good conversation; it keeps the user interested, responds to their actions, and encourages them to come back for more.
Cultural and societal influences play a crucial role in shaping preferences and perceptions
1. Consider Cultural and Societal Influences: Factor in the diverse cultural and societal backgrounds of your audience to ensure your design resonates broadly and respectfully.
2. Understand Industry and Context of Use: Tailor your design to align with the specific industry norms and the practical context in which your interface will be used.
3. Embrace User Demographics: Embrace the diversity in user demographics, incorporating insights about age, gender, profession, and other factors to craft a more tailored and effective interface.
4. Adapt to Your Audience’s Tech-Savviness: Customize your interface to suit the specific tech-savviness level of your target audience

The Nielsen Norman Group’s research across different demographics — highlighting the unique online behaviors and expectations of young adults, the evolving digital literacy and specific usability needs of seniors, and the distinct and varying design requirements for children — emphasizes the critical importance of empathetic and user-centric design in user interface development to cater effectively to each group’s unique characteristics and preferences.
A well-planned layout is not just about placing elements on a screen; it’s about creating a visual symphony that directs, delights, and engages users
5. Embrace Negative Space: Use negative space wisely to create a clean, uncluttered interface that highlights the most important elements and improves readability.
6. Use the Golden Ratio or Rule of Thirds: Incorporate the Golden Ratio or the Rule of Thirds in your design to achieve natural balance and aesthetically pleasing proportions.
7. Establish a Clear Hierarchy with Size, Color, and Spacing: Utilize variations in size, color, and spacing to create a visual hierarchy that guides the user’s eye to the most significant information first.
8. Utilize Grid Systems: Implement grid systems to bring structure and consistency to your layout, ensuring a cohesive and harmonious arrangement of elements.
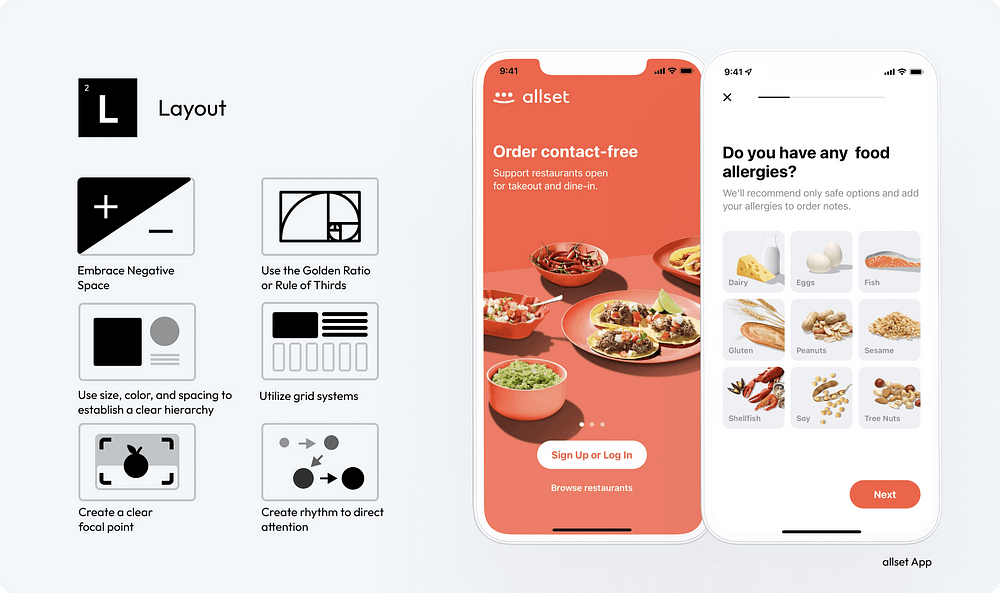
9. Create a Clear Focal Point: Designate a clear focal point in your layout to capture immediate attention and orient the user’s interaction with your content.
10. Create Rhythm to Direct Attention: Employ rhythmic design elements, such as repeated patterns or structured layouts, to create a visual flow that intuitively directs the user’s attention through the interface.
In addition, consider utilizing F and Z-pattern layouts to match users’ natural scanning habits. Employ the F-pattern in text-dense interfaces, strategically placing crucial information at the top and left.
Simplicity is ultimate sophistication
It’s about stripping away the non-essential elements and focusing on what truly matters to the user.
11. Achieve Simplicity Through Thoughtful Reduction: Prioritize content and features, removing anything non-essential. Focus on the core functionalities to create a streamlined and more user-friendly interface.
12. Organization Helps the System of Many Look Fewer: Use clear categorization and grouping of elements. Implement drop-down menus or tabs to organize content, making the interface less cluttered and more navigable.
13. Don’t Make Users Think: Ensure that navigation and task flows are logical and predictable. Use common UI elements and place them where users expect them to be, reducing cognitive load.
14. Good Design is as Little Design as Possible: Adopt a minimalist approach, using only elements that are necessary for functionality. Avoid excessive use of colors, fonts, and graphics to maintain a clean and focused interface.
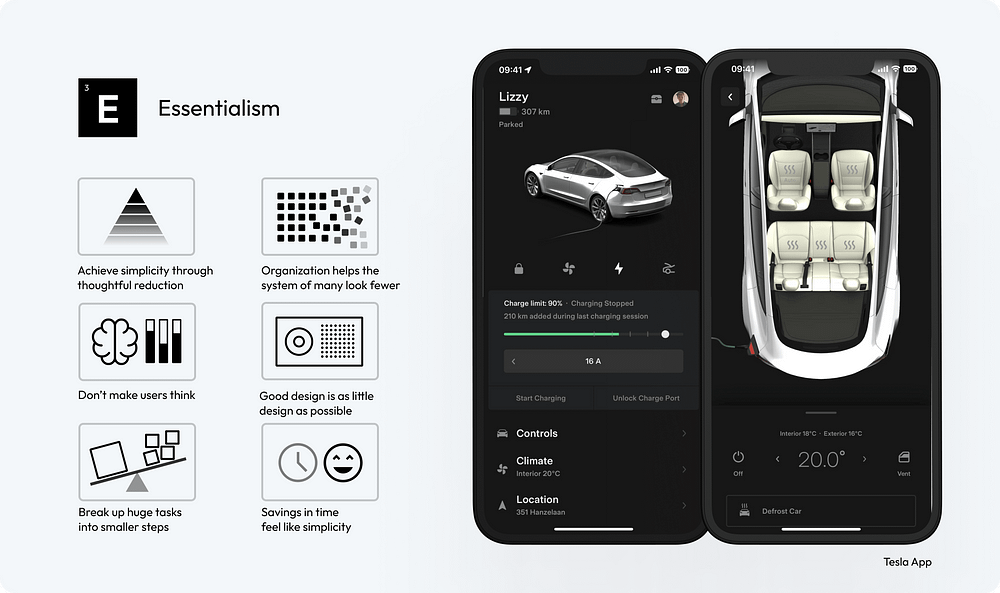
15. Break Up Huge Tasks into Smaller Steps: Design complex processes, like forms or multi-step tasks, into smaller segments. Use progress bars or breadcrumbs to visually indicate the user’s progress and what remains.
16. Savings in Time Feel Like Simplicity: Optimize load times and streamline processes to make interactions quicker. Use smart defaults, autocomplete features, and predictive text to speed up user input and decision-making.
You can find more recommendations in How to simplify your design.
It’s not just about leading the user from point A to point B; it’s about creating a journey that feels natural, effortless, and engaging
The art of designing a user interface involves guiding the user through a digital landscape with intuition and ease.
17. Craft Engaging User Onboarding: Start by designing an engaging onboarding process that educates users about your product from the first interaction. Effective onboarding lays the foundation for the user’s entire experience with your interface.
18. Ensure an Intuitive Flow: Develop your interface with a logical, step-by-step flow that feels natural and requires minimal effort for users to navigate, enhancing their overall experience.
19. Offer Contextual Hints and Tips: Implement contextual assistance such as tooltips, pop-ups, or inline instructions that appear when users need them, aiding in their understanding and use of the interface.
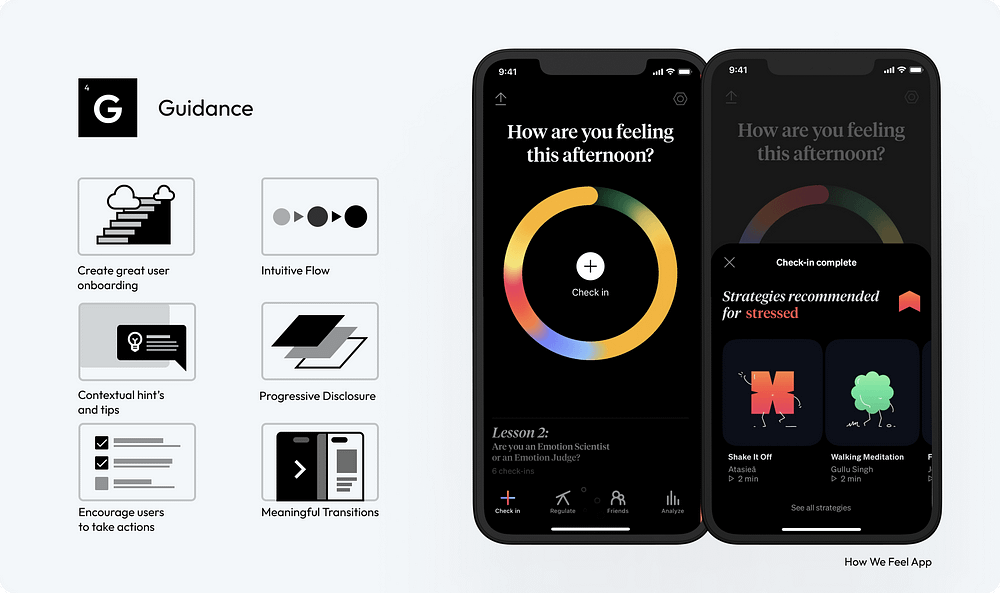
20. Implement Progressive Disclosure: Strategically reveal information to users, showing only what’s necessary at each step. This approach helps maintain a clean interface and focuses the user’s attention on immediate tasks.
21. Design to Encourage User Actions: Use clear design elements like buttons, icons, and calls to action to guide users towards desired interactions, ensuring these elements are prominent and easily accessible.
22. Provide Feedback for User Actions: Create a system that offers immediate visual or auditory feedback for user actions, acknowledging their interactions and guiding them to the next step in the interface.
Masterfully applied typography helps you stand out, enhance readability and aesthetic appeal
23. Establish Typography Hierarchy: Create a clear hierarchy using different font sizes, weights, and styles to guide the user’s attention to the most important content first.
24. Prioritize Readability: Choose fonts that are easy to read on various devices and screen sizes. Legibility should be a top priority, especially for body text.
25. Reflect Brand Mood: Select fonts that align with your brand’s personality. Whether it’s professional, playful, or elegant, typography should reinforce the brand’s tone.

26. Pair Fonts Wisely: When combining multiple fonts, ensure they complement each other.
27. Limit Font and Style Variations: Too many font types or styles can create a cluttered and confusing interface. Stick to a limited set to maintain a clean and cohesive look.
28. Adjust Line Spacing, Kerning, and Line Height: Proper spacing between letters (kerning), words, and lines improves readability and text flow. Experiment with different settings to find the most visually appealing and readable format.
The right color choices can make a significant difference in how users perceive and interact with a product
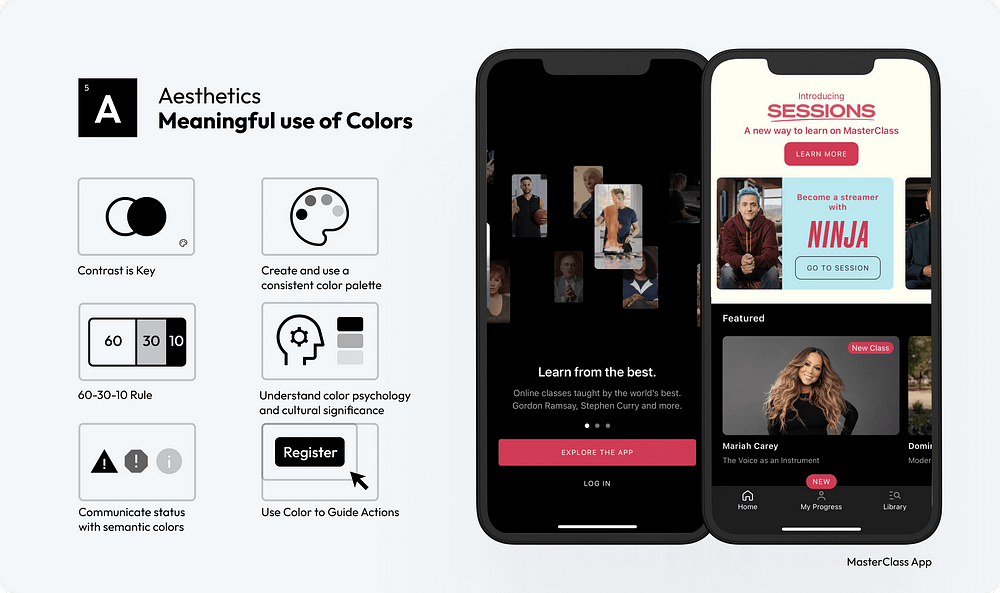
29. Contrast is Key: Ensure sufficient contrast between text and background to enhance readability and accessibility.
30. Create and Use a Consistent Color Palette: Develop a consistent color palette that reflects your brand identity and use it consistently across your interface to maintain visual coherence.
31. Use the 60–30–10 rule for balancing colors: — 60% dominant color, 30% secondary color, and 10% accent color, to create a visually harmonious interface.
32. Understand Color Psychology and Cultural Significance: Consider how different colors evoke different emotions and meanings in various cultures. Tailoring your color choices to your audience can enhance the user experience and avoid cultural missteps.
33. Communicate Status with Semantic Colors: Use colors to communicate status intuitively, like red for errors or green for success, to help users understand system feedback quickly.
34. Use Color to Guide Actions: Utilize color strategically to highlight key actions, like buttons or links, guiding the user’s attention to important interactions.
Effective visual content in UI design enhances user engagement and emotional connection
35. Prioritize Content Over Excessive UI Styling: Focus on delivering content through visuals without overwhelming the user with excessive UI decorations. Let the visuals speak for themselves.
36. Purposeful Imagery and Illustrations: Use imagery and illustrations that add meaning to your content. Avoid generic stock photos; opt for custom or carefully selected images that reflect the brand’s identity and message.
37. Keep Text Concise and Straightforward: Complement visuals with clear and concise text. Avoid long paragraphs and opt for bullet points or short descriptions that enhance the visual message.

38. Micro-Interactions & Delightful Animations: Incorporate subtle animations and micro-interactions that enhance user engagement without detracting from the main content.
39. Use Video for Dynamic Storytelling: Implement video content to tell stories or explain complex concepts dynamically. Videos can be particularly effective in conveying messages that are difficult to express through static images.
40. Incorporate High-Quality Product Shots or Renders: For e-commerce and product-based interfaces, use high-quality photographs or 3D renders of products. Detailed and attractive product visuals can significantly boost user interest and sales.
Innovative or unique interfaces will create memorable experiences, leading to higher user satisfaction.
41. Strive for Originality and Uniqueness: Create UI designs that stand out with original concepts and unique elements, differentiating your product in a crowded market.
42. Leverage the Latest Technology: Stay abreast of emerging technologies and consider how they can be incorporated into your design to offer cutting-edge experiences.
43. Be the Most Advanced, Yet Acceptable: Push the boundaries of innovation, but ensure your designs remain user-friendly and accessible to your target audience.
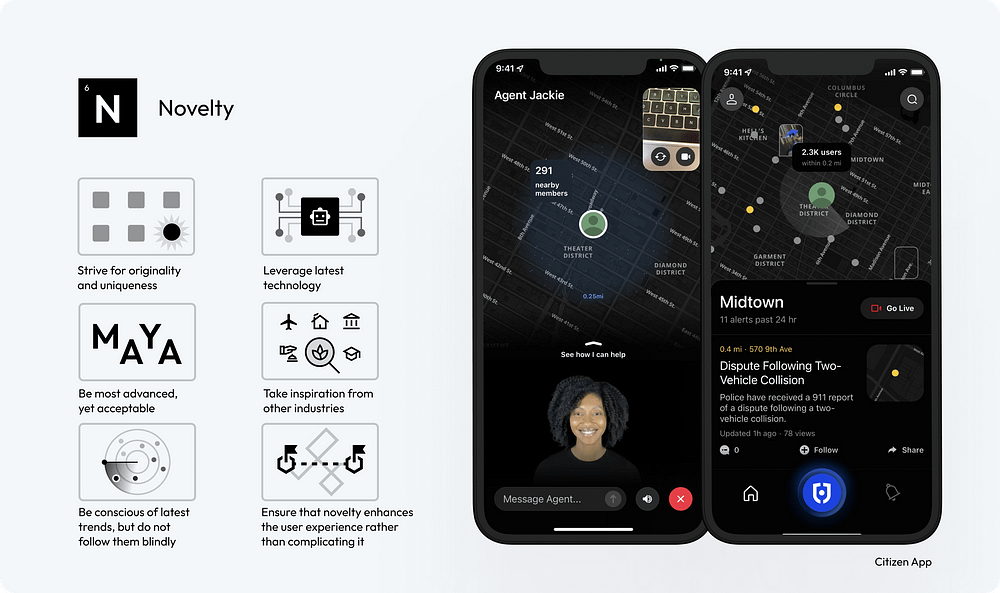
44. Take Inspiration from Other Industries: Look beyond the field of UI design for inspiration, drawing creative ideas from art, architecture, nature, and more.
45. Be Conscious of Latest Trends, But Do Not Follow Them Blindly: Stay informed about current design trends, but use them judiciously to ensure your design maintains its unique identity.
46. Ensure that Novelty Enhances the User Experience Rather Than Complicating It: Novelty should always serve a purpose, enhancing the overall user experience without adding unnecessary complexity.
Consistency creates a sense of familiarity and helps build trust and confidence
47. Develop a Comprehensive Design System: A design system acts as a single source of truth for all design elements, ensuring uniformity across all aspects of the UI.
48. Limit Design Patterns: Using a consistent set of design patterns simplifies the user’s interaction model, making the interface more predictable and user-friendly.
49. Ensure Predictability in Element Behavior: Interface elements should behave consistently throughout the application, so users know what to expect from their interactions.
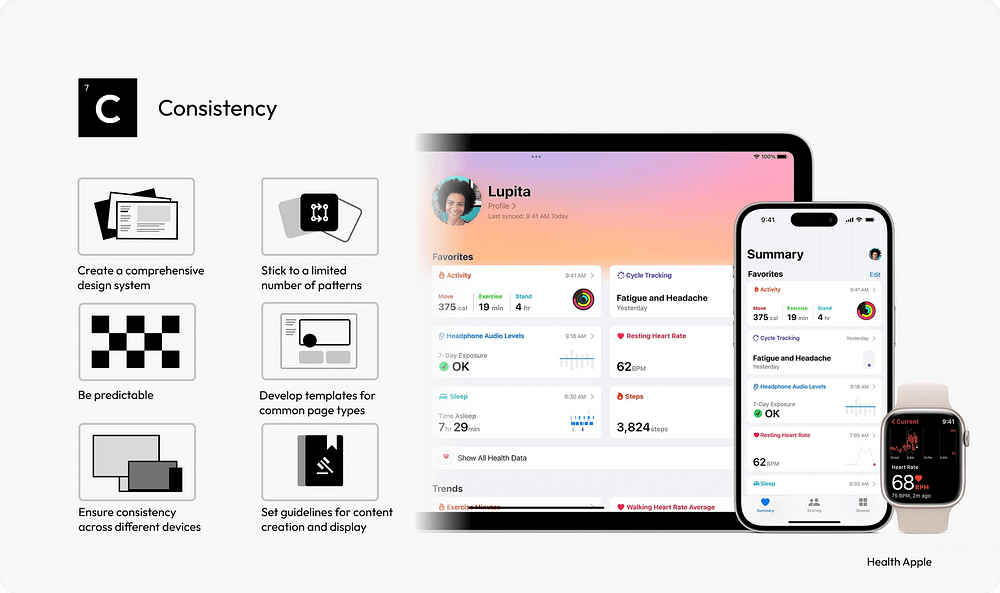
50. Use Standardized Templates: For common page types, standardized templates provide a consistent structure, aiding in user navigation and content comprehension.
51. Maintain Cross-Device Consistency: A consistent UI across different devices and platforms enhances the user experience, making the interface more approachable and accessible.
52. Standardize Content Guidelines: Consistent tone, style, and formatting in content presentation help maintain a coherent narrative across the interface.
Create a more immersive user experience that entertains
53. Introduce Gamification Elements: Incorporate game mechanics like points, badges, and leaderboards to motivate users and encourage interaction.
54. Personalization and Customization: Offer users the ability to customize their experience. Personalization can increase the relevance of the interface to the individual user, enhancing engagement.
55. Utilize Storytelling Techniques: Embed narrative elements in the UI to create a more compelling and memorable user experience. Storytelling can guide users through the interface in an engaging way.
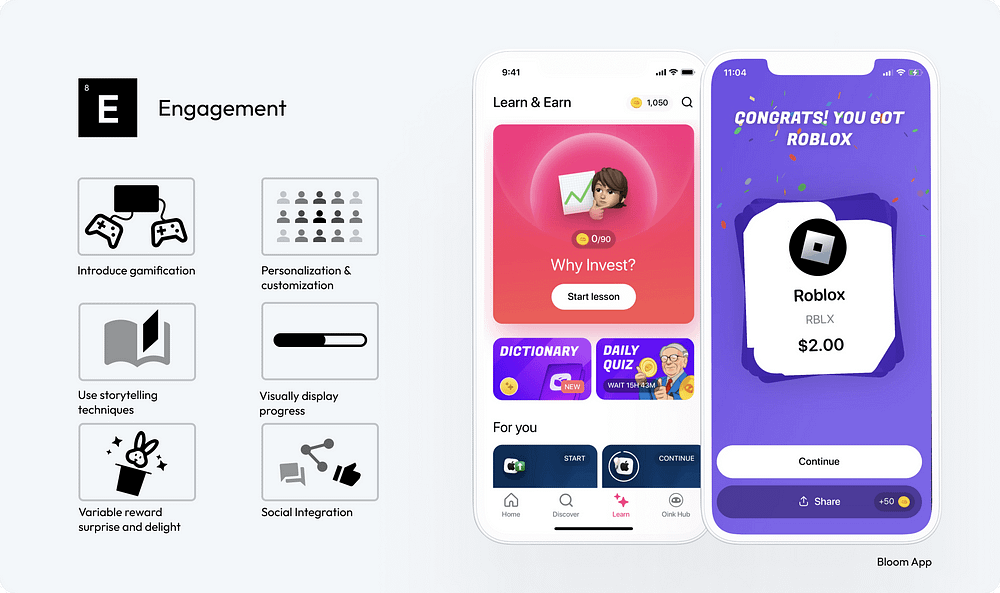
56. Visually Display Progress: Use visual indicators like progress bars to show users their achievements and progression. This can increase motivation and sense of accomplishment.
57. Incorporate Variable Reward Mechanisms: Implement elements of surprise and delight, such as unexpected rewards or bonuses, to keep users engaged and curious.
58. Integrate Social Features: Include social integration features like sharing achievements or competing with friends to foster a sense of community and encourage continued engagement.
Thank you for reading! If you found these insights helpful, don’t miss out on my poster of “58 Rules for Stunning and Effective User Interface Design.” It’s a practical checklist that you can use to elevate your design skills. You can find it here.
https://www.figma.com/community/file/1326467076529354215/poster-58-rules-for-stunning-and-effective-user-interface-design
'프로그래밍 > Style & Design' 카테고리의 다른 글
| 비전 프로 출시 D-2 (0) | 2024.01.31 |
|---|---|
| 10 Powerful CSS Properties that Every Web Dev must know (0) | 2023.08.29 |
| [ICON] ion-icon 아이콘 사용하기 (0) | 2023.08.24 |
| [CSS] Magic inspired Social Share Button (0) | 2023.08.24 |
| Best 15 CSS Trends To Watch For 2023 (0) | 2023.07.04 |