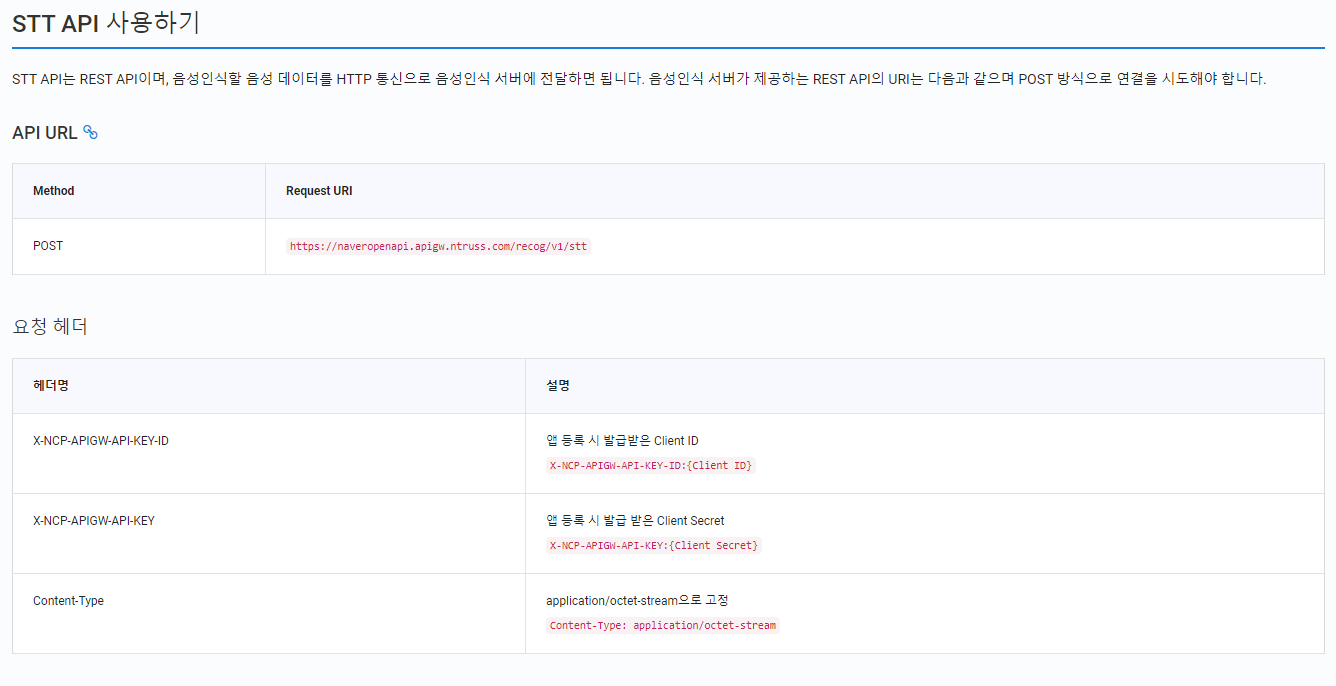
https://apps.apple.com/us/app/otter-transcribe-voice-notes/id1276437113
Otter: Transcribe Voice Notes
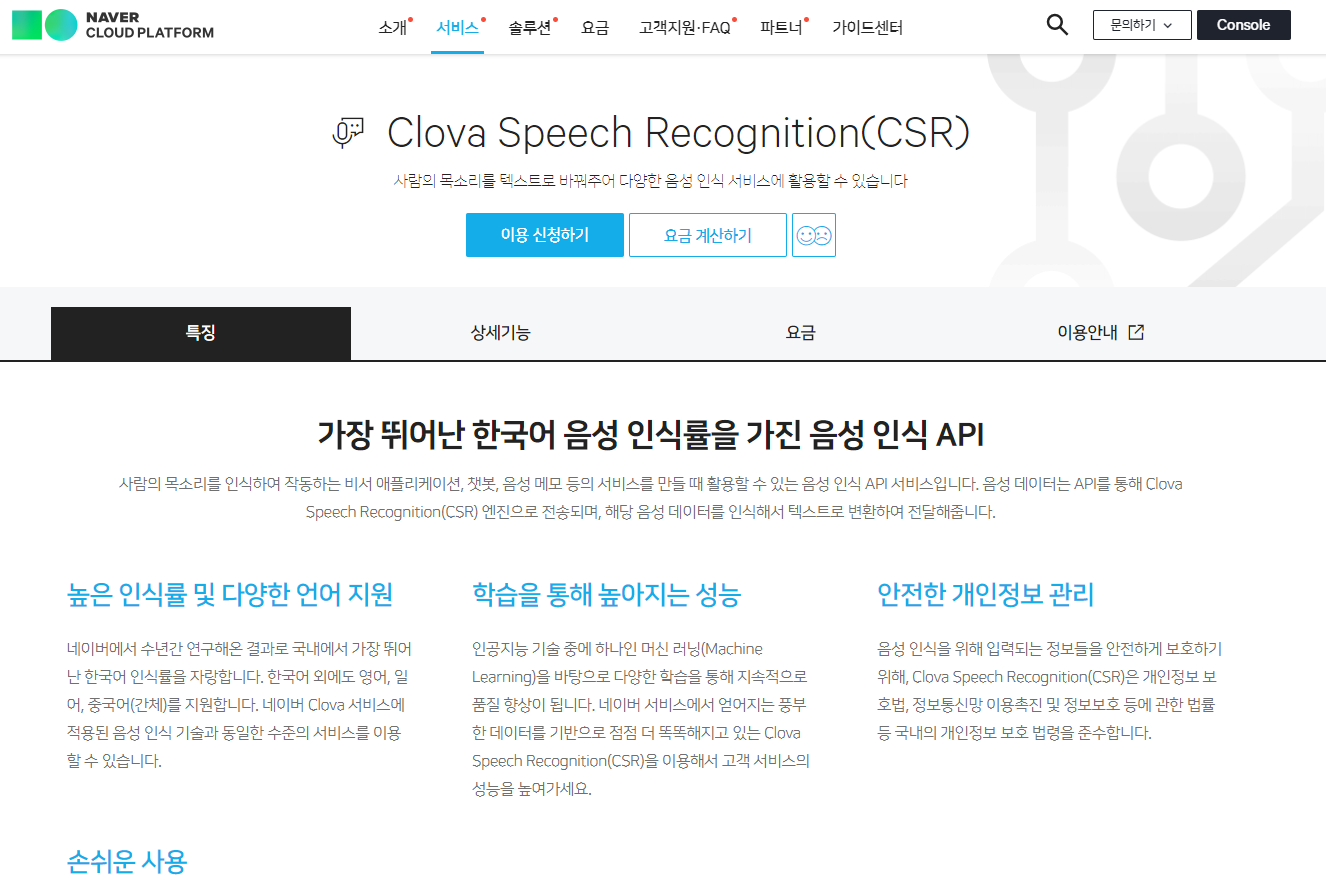
OtterPilot™ your meetings with AI. Get a meeting assistant that records audio, writes notes, automatically captures slides, and generates summaries. Otter transcribes all your meetings, interviews, lectures, and everyday voice conversations in real ti
apps.apple.com

Zoom, Google Meet, Microsoft Teams 등을 위한 자동 회의 메모. 집에서 일할 때 연결 상태를 유지하고 협업하세요.
OtterPilot™ AI와의 회의. 오디오를 녹음하고, 메모를 작성하고, 슬라이드를 자동으로 캡처하고, 요약을 생성하는 회의 도우미를 받으세요.
Otter는 모든 회의, 인터뷰, 강의 및 일상적인 음성 대화를 실시간으로 기록하므로 토론에 집중할 수 있습니다. 대면, Zoom, Google Meet 및 Microsoft Teams에 대한 자동 메모를 받으세요. 모든 메모는 검색 및 공유가 가능합니다. Otter.ai는 웹에서도 사용할 수 있습니다. 영어만 가능합니다.
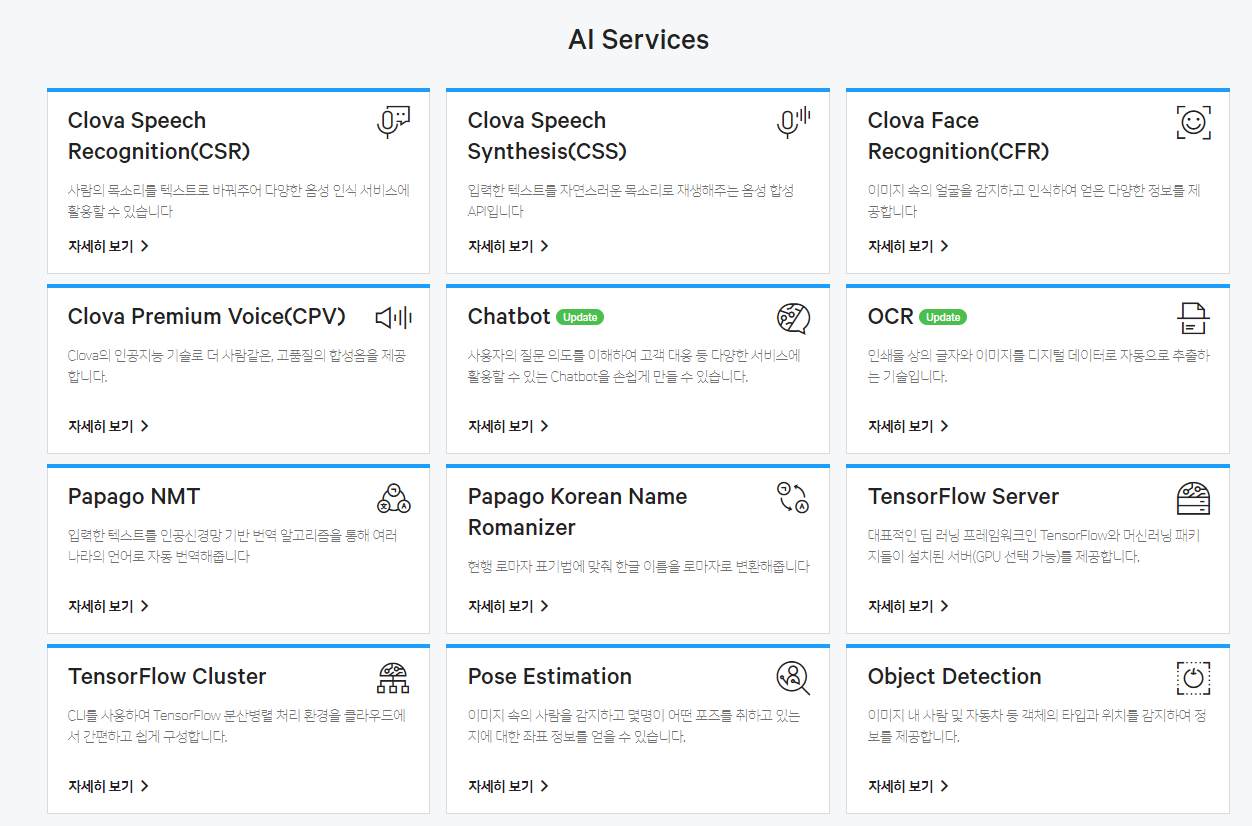
많은 용도
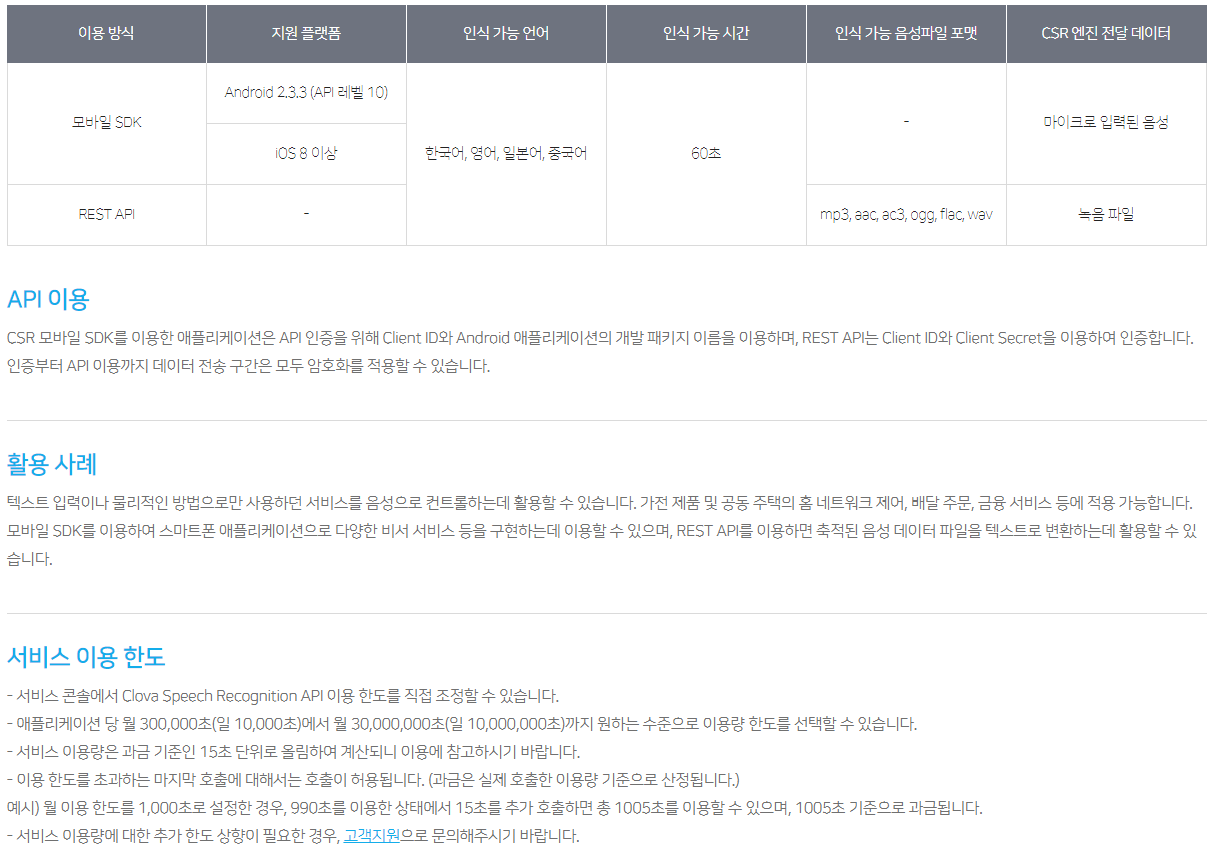
• 회의 메모를 자동으로 작성하고 팀원과 공유하여 모두 동기화 상태 유지
• 인터뷰, 강의, 팟캐스트, 비디오, 웨비나, 기조연설을 녹음하고 필사합니다.
• 청각 장애인 커뮤니티, ESL 학습자 및 접근성이 필요한 모든 사람에게 실시간 자막 제공
실시간 녹음 및 전사
• 위젯과 바로가기를 사용하여 탭 한 번으로 즉시 녹음
• 높은 정확도로 실시간(온라인일 때) 기록
• 나중에 검토할 핵심 사항 강조표시
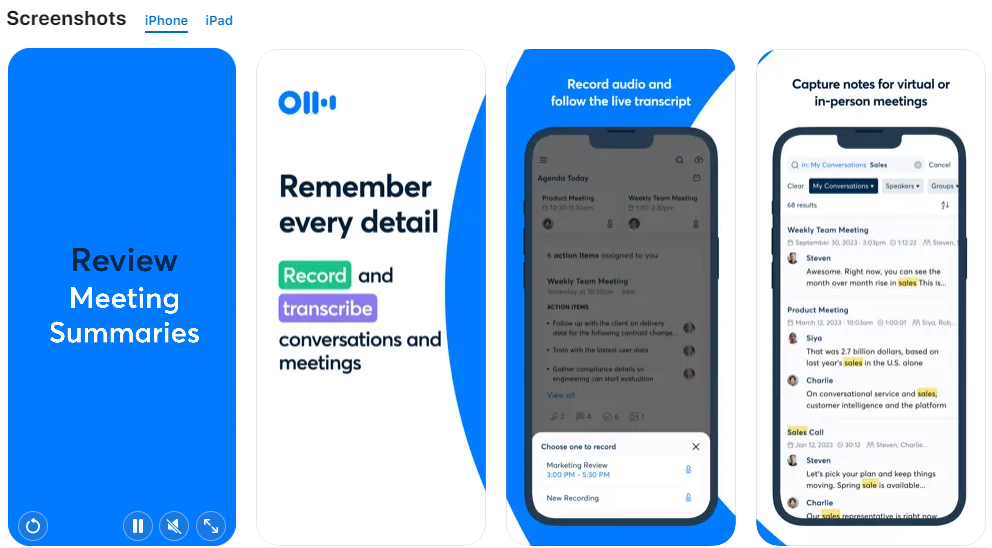
• 화이트보드 토론, 슬라이드 등의 사진을 삽입합니다.
• 내장 마이크 또는 블루투스 장치를 통해 오디오 입력
AI로 메모 강화
• 단락을 자동으로 구두점, 대문자 및 구분
• 화자 식별(일부 교육 후)
• 워드 클라우드 및 요약 키워드를 생성합니다. 단어를 탭하면 말한 곳으로 이동합니다.
• 가상 회의 중 자동화된 슬라이드 캡처
• 모든 회의 후 자동 요약
공유 및 협업
• 그룹 내에서 녹음을 시작하여 대본을 실시간으로 공유
• 그룹 구성원을 초대하여 함께 보고 편집하고 강조 표시합니다. 모든 하이라이트는 Takeaways 패널에서 캡처됩니다.
• 요점 패널 내에서 의견을 추가하고 작업 항목을 할당합니다.
• 링크를 통해 외부에 공유
검색 및 재생
• 전체 오디오를 스크러빙할 필요가 없도록 텍스트 검색
• 조정 가능한 속도로 재생
• 오디오가 재생되는 동안 강조 표시된 단어를 따라가세요.
• 단어를 탭하면 오디오가 해당 지점으로 이동합니다.
편집 및 강조 표시
• 텍스트를 편집하여 오류를 수정하십시오.
• 화자에게 태그를 지정하여 단락에 라벨을 지정하고 Otter가 화자를 식별하도록 교육
• 탭 한 번으로 문장 강조 표시
구성 및 내보내기
• 대화를 개인 폴더로 정리
• 클립보드에 복사하거나 다른 앱에 직접 공유
• PDF, TXT, SRT, MP3로 내보내기
가져오기 및 동기화
• 오디오 및 비디오 파일 가져오기
• Zoom 계정을 동기화하여 클라우드 녹음 기록
• 다른 통화 녹음 앱에서 업로드
• 캘린더를 동기화하여 회의를 기록하고 메모에 자동 제목을 지정하도록 알림
• 간편한 공유를 위해 연락처 가져오기
iOS에 최적화
• Siri 바로가기 및 홈 위젯으로 녹음 시작/중지
• AirPods를 통해 녹음
• iOS 캘린더, 연락처 및 카메라와 동기화
• 3D Touch로 대화 미리보기
• 얼굴/터치 ID로 잠금
• AirPrint를 통한 인쇄
• Dynamic Type으로 글꼴 크기 조정
수달 프로
• 재생 속도 향상 및 무음 건너뛰기
• 대량 내보내기
• 월별 청구를 선택하거나 연간 청구로 크게 절약
• 결제는 구매 확인 시 iTunes 계정으로 청구됩니다.
• 현재 기간이 종료되기 최소 24시간 전에 자동 갱신을 해제하지 않으면 구독이 자동으로 갱신됩니다.
• 현재 기간이 끝나기 24시간 이내에 계정에 갱신 비용이 청구됩니다.
• 설정에서 구독을 관리할 수 있으며 구매 후 계정 설정으로 이동하여 자동 갱신을 끌 수 있습니다.
• 무료 평가판 기간 중 미사용 부분은 제공되는 경우 구독 구매 시 자격이 상실됩니다.
"Otter.ai는 기록된 생각을 글로 옮기는 보석입니다" - Forbes 2023
"2019년 우리가 사랑하는 앱" – App Store
"2018년 최고의 앱 7개" – Mashable
"2018년 최고의 신규 앱 25개" – Fast Company
우리는 보안과 프라이버시를 중요하게 생각합니다. 귀하의 데이터는 기밀이며 제3자에게 전송되지 않습니다. 귀하는 귀하의 계정에서 귀하의 데이터를 삭제할 수 있는 모든 권한이 있습니다.
도움이 필요하다? 도움말 센터를 확인하세요: https://help.otter.ai
서비스 약관: https://otter.ai/terms-of-service
개인 정보 보호 정책: https://otter.ai/privacy-policy
Automated meeting notes for Zoom, Google Meet, Microsoft Teams, and more. Stay connected and collaborative when you work from home.
OtterPilot™ your meetings with AI. Get a meeting assistant that records audio, writes notes, automatically captures slides, and generates summaries.
Otter transcribes all your meetings, interviews, lectures, and everyday voice conversations in real time, so you can focus on the discussion. Get automated notes for: in-person, Zoom, Google Meet, and Microsoft Teams. All notes are searchable, and shareable. Otter.ai is also available on the web. English only.
Many Uses
• Take meeting notes automatically, and share with teammates to keep everyone in sync
• Record and transcribe interviews, lectures, podcasts, videos, webinars, keynotes
• Provide live captioning to the deaf and hard-of-hearing communities, ESL learners, and anyone with accessibility needs
Record & Transcribe Live
• Record instantly in one tap, with widget and shortcut too
• Transcribe in real time (when online) with high accuracy
• Highlight the key points to review later
• Insert photos of whiteboard discussions, slides, etc.
• Input audio via built-in mic or Bluetooth device
Enrich Notes with AI
• Punctuate, capitalize, and break paragraphs automatically
• Identify speakers (after some training)
• Generate word clouds and summary keywords; tap on a word to jump to where it was said
• Automated Slide Capture during virtual meetings
• Automated Summary after all meetings
Share & Collaborate
• Start a recording inside a group to share the transcript live
• Invite group members to view, edit, and highlight collaboratively. All highlights will be captured in the Takeaways panel.
• Within the Takeaways panel, add comments and assign action items
• Share externally via links
Search & Playback
• Search the text so you don't have to scrub through the whole audio
• Playback at adjustable speeds
• Follow along the highlighted word as the audio is playing
• Tap on any word to jump the audio to that spot
Edit & Highlight
• Edit the text to correct any errors
• Tag the speakers to label the paragraphs and train Otter to identify speakers too
• Highlight sentences in one tap
Organize & Export
• Organize conversations into personal folders
• Copy to clipboard, or share directly to other apps
• Export as PDF, TXT, SRT, MP3
Import & Sync
• Import audio and video files
• Sync your Zoom account to transcribe cloud recordings
• Upload from other call recording apps
• Sync your calendars to be reminded to record your meetings and auto-title your notes
• Import your contacts for easy sharing
Optimized for iOS
• Start/Stop recording with Siri Shortcut & home widget
• Record via AirPods
• Sync with iOS Calendar, Contacts & Camera
• Preview conversations with 3D Touch
• Lock with Face/Touch ID
• Print via AirPrint
• Adjust font size with Dynamic Type
Otter Pro
• More playback speeds and skip silence
• Bulk export
• Choose either monthly billing or save big with yearly billing
• Payment will be charged to your iTunes Account at confirmation of purchase
• Subscription automatically renews unless auto-renew is turned off at least 24-hours before the end of the current period
• Account will be charged for renewal within 24-hours prior to the end of the current period
• You can manage your subscriptions in Settings and auto-renewal may be turned off by going to your Account Settings after purchase
• Any unused portion of a free trial period, if offered, will be forfeited when you purchase a subscription
“Otter.ai Is A Gem For Transcribing Your Recorded Thoughts Into Writing” - Forbes 2023
"Apps We Love 2019" – App Store
"7 Best Apps of 2018" – Mashable
"25 Best New Apps of 2018" – Fast Company
We take security and privacy seriously. Your data is confidential and will not be transferred to third parties. You have full control to delete your data from your account.
Need help? Check out our Help Center: https://help.otter.ai
Terms of Service: https://otter.ai/terms-of-service
Privacy Policy: https://otter.ai/privacy-policy
'프로그래밍 > App' 카테고리의 다른 글
| Flutter and Clean Architecture(I) (0) | 2023.08.29 |
|---|---|
| [Flutter] Flutter vs React Native (0) | 2023.08.11 |
| [Flutter] What is Flutter Impeller? (0) | 2023.08.03 |
| What’s new in Flutter 3.10 (0) | 2023.08.03 |
| Flutter Web in 2023 — is it good for you? (0) | 2023.07.14 |